刘艳秋a,王 浩a,张 颖a,蔡 超b
(沈阳工业大学 a.理学院,b.管理学院,沈阳 110870)
摘 要:针对已存在的多级物流服务供应链订单分配中没有充分考虑客户的最佳配送时间和需求的问题,提出了在大数据背景下,利用大数据的知识分析客户的点击量、浏览时间和销量之间的关联性,预测客户的需求、分析客户的位置数据来预测客户的最佳配送时间.基于大数据的预测结果,以物流服务集成商最小化服务成本为目标,建立三级物流服务供应链的订单分配优化模型,并通过实例仿真进行了验证.结果表明,基于大数据预测的销量和配送时间更贴近客户实际需求,在保证客户服务质量的情况下,获得问题的最优解.
关 键 词:三级物流服务供应链;大数据;订单分配;服务水平;关联规则;用户行为规律;时间预测;需求预测
物流服务供应链优化问题是2004年由Ellram[1]在《Journal of supply chain management》一文中第一次提出的,并且定义了物流服务供应链的概念.物流服务供应链是由物流服务集成商、功能型物流服务提供商及客户模式构成.物流服务集成商在接收到客户的订单需求后,对客户的订单需求进行统一整合规划后将订单分配给服务提供商,由各个服务提供商完成物流服务任务,该过程称为订单需求任务分配过程.随着大数据时代的到来,互联网等信息技术的飞速发展和人民生活水平不断地提高,人们对物流服务水平的要求也越来越高.因此,在大数据时代,根据客户数据分析客户的喜好,并根据客户的喜好合理地分配订单任务,优化整个物流服务供应链的服务成本,才能更好地提高企业的竞争力和信誉,为企业带来长远的利益.
在研究物流服务供应链优化的过程中,主要集中研究了订单任务分配问题,文献[1-2]在订单分配问题中都考虑了物流服务集成商和分包商之间交易费用,应用相应的遗传算法进行求解;刘伟华等[3-4]以物流服务集成商成本最小化、功能提供商满意度最大化为目标函数,构建了三级物流服务供应链的订单任务分配的双层优化模型,并利用遗传算法进行求解;范琛[5]等提出在信息更新下多期多任务多目标的动态订单分配优化模型;文献[6]将Stackelberg博弈模型引入到服务供应链中;范志强等[7]考虑了不良产品的特点,建立了多目标混合整数优化模型,并用模拟退火算法进行求解;文献[8-9]分别提出了面向价值服务的供应链优化模型和基于模糊线性规划的供应商选择订单分配模型;李阳珍[10]将时间可靠度引入到物流服务供应链中,构建了基于可靠度,物流能力约束利润最大化模型,并考虑了客户的可靠性需求以及物流服务的水平质量.
将大数据与物流服务供应链优化结合的研究相对较少,所以本文在大数据背景下,提出物流服务供应链订单分配任务中两方面的改进.一方面是基于客户的大数据分析,不再利用概率分布或对数据进行抽样分析,而是根据客户的全部数据去预测分析,这样的预测结果更贴近实际.本文将根据客户的网上点击量、浏览时间和销量数据,分析它们三者之间的关联去预测客户的需求量,以往的物流服务普遍通过缩短配送时间来提高服务质量,但是配送速度快并不一定是客户最佳的配送时间[11-12],所以,本文将会根据客户海量的位置数据去分析客户的行为规律,预测客户最佳的配送时间.另一方面,基于大数据分析预测的结果及客户的个性化需求与供应商提供的服务能力进行匹配,给出吸引力的决策变量,选择客户最满意的供应商进行服务,从而提高客户的服务质量,提升企业信誉,在此基础上降低企业成本,为企业的长久发展带来更多的利润.
1.1 问题描述
为了提高服务水平及客户的满意度,本文将客户终端的预期要求及预测数据结果引入到物流服务供应链里,建立由物流服务集成商、功能提供配送商和客户构成的三级物流服务订单分配模型[13],以最小化物流服务成本为目标,同时在供应商能参与提供服务的最小利润的约束下,根据客户要求与大数据预测结果来选择客户最满意的供应商来提供服务.
1.2 变量描述及条件假设
模型的建立基于以下假设:
1) 不考虑产品的质量和类别的差异性;
2) 一个配送点可以为多个客户服务,但是一个客户只能接受一个配送节点的服务;
3) 客户的位置数据已知.
模型建立过程中变量描述如下:n表示功能提供商个数,m表示基于大数据预测的需求数量,也就是销售的数量,Aij表示功能提供商i对客户j的吸引力[14],qi表示第i个功能提供商的配送量,cij表示功能提供商的服务成本,pij为功能提供商i对客户j的服务报价,Qij表示功能提供商i对j的服务水平,pj表示客户可接受的最高价格,Qj表示客户预期的服务水平,γj表示客户对价格变化的敏感系数,θj表示客户对服务水平的敏感系数,Hi表示功能提供商的利润,Si表示功能提供商所能参加服务的最小利润,xi表示功能提供商i最大服务能力,ci表示提供产品的价格.
1.3 模型建立
三级物流服务供应链里,物流服务成本由各个功能配送商的报价和时间惩罚成本构成,其目标函数为
min ![]()
(1)
s.t.![]()
(2)
Aij=[1+(pj-pij)/pj]γj(Qij/Qj)θj
(3)
![]()
(4)
![]()
(5)
![]()
(6)
![]()
(7)
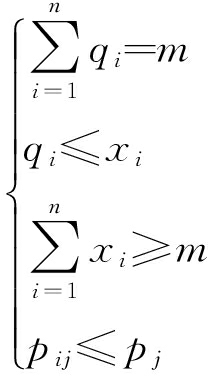
(8)
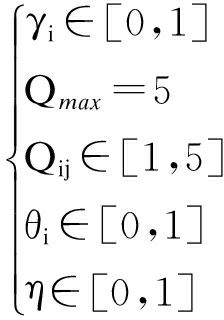
(9)
优化模型的目标式(1)为最小化物流服务供应链总费用,包括功能提供商的服务费和未及时送到货的惩罚费;函数式(2)为决策变量,表示选择客户吸引力高的功能提供商;式(3)为客户吸引力表达式,不考虑产品质量有差异的情况下,物流服务水平越高,对客户的吸引力越高,相应的物流成本就越高,物流成本高,那么功能提供商的服务报价相对就高,从而会降低对客户的吸引力,所以本文将功能提供配送商i对客户j的吸引力用式(3)表示;式(4)为配送的时间惩罚成本,t0为实际送达的时间,tj为客户期望的最佳配送时间,是基于大数据预测得出,π为惩罚系数,在tj内送到则不对其惩罚;式(5)为功能提供商被分配的量,a0为客户点击量和浏览时间同时发生与销量之间的关联度,T(A∩B)为客户点击率与浏览时间同时发生的数量;式(6)为功能提供商参加服务的最小利润约束;式(7)为物流服务成本,η为服务成本系数;式(8)依次表示的约束为所有的需求量必须全部配送、每个配送商i的服务量不能超过本身最大的服务能力、选出的配送商必须满足所有客户的需求、服务报价不能超过客户能接受的最高报价.式(9)约束各变量的取值范围.
2.1 客户需求预测
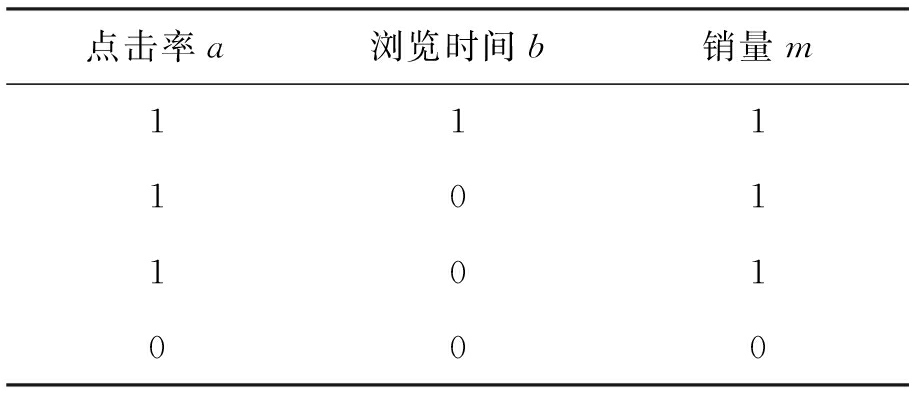
在大数据背景下,根据客户的点击率、浏览时间、购物车、评价信息中所有与销量有关的数据都可以预测商品的销量.如果近期某个产品的点击率暴涨,那么相应的产品也是近期的热卖产品,所以点击率和销量之间必然存在的一定的相关性.而浏览时间的限定保证了本次点击的有效性,而不是误点或者恶意点击,所以本文同时考虑点击率、浏览时间与销量之间的关联关系来预测销量.设销量为m,点击率为和浏览时间分别为a、b,选取大量用户近期的点击数据,定义点击选中为1,否则为0,浏览时间超过30 s为1,否则为0,购买为1,否则为0,网页数据如表1所示.
表1 客户的网页数据
Tab.1 Webpage data of customers
根据关联的支持度和置信度来进行评判,其表达式分别为
![]()
(10)
![]()
(11)
式(10)为规则支持度,表示简单的关联规则,支持度低则说明规则不具有一般性,![]() 为事件X与事件Y同时发生的事务数,
为事件X与事件Y同时发生的事务数,![]() 为事务总数;式(11)为规则置信度,表示简单关联规则的准确度,如果置信度高,则说明事件X出现的条件下,事件Y出现的概率大,
为事务总数;式(11)为规则置信度,表示简单关联规则的准确度,如果置信度高,则说明事件X出现的条件下,事件Y出现的概率大,![]() 为事件X出现的个数.只有当置信度和支持度达到设定最小支持度时规则才成立,所以本文根据Apriori算法,挖掘产生满足最小支持度的候选集,得到关联度.设根据预测的销量总数为m,则由公式m=a0T(A∩B)计算客户需求量m.
为事件X出现的个数.只有当置信度和支持度达到设定最小支持度时规则才成立,所以本文根据Apriori算法,挖掘产生满足最小支持度的候选集,得到关联度.设根据预测的销量总数为m,则由公式m=a0T(A∩B)计算客户需求量m.
2.2 客户配送时间预测
设客户的位置坐标为(xn,yn,tn),xn、yn表示客户位置的横纵坐标,tn表示客户的相应位置的时间数据.根据用户的位置数据利用分段技术将用户一天的时间进行分段,分段后将所有位置距离不大于设定最小距离的位置进行聚类,并将其位置改为和聚类中心一致的位置坐标,然后再利用关联规则去分析用户的行为.
2.3 最佳配送时间
客户最佳配送时间预测算法如下:
1) 输入时间序列,令i=1,首先处理第一列数据,定义distance=A(i),distance(i,1)=![]() ,设定index=distance≤0.5,从中筛选出所有与中心点满足条件的数据,合并相同的数据可得Q11=(x11,y11,t11,t1j),j为相同位置数据最后的一个时间点,循环处理所有数据得到Qij;
,设定index=distance≤0.5,从中筛选出所有与中心点满足条件的数据,合并相同的数据可得Q11=(x11,y11,t11,t1j),j为相同位置数据最后的一个时间点,循环处理所有数据得到Qij;
2) 输入Qij,根据![]() ≤y11找出所有满足条件的Qij,并将其赋值为Q11,循环找出所有相同位置的坐标并进行聚类,其中,δ为邻域;
≤y11找出所有满足条件的Qij,并将其赋值为Q11,循环找出所有相同位置的坐标并进行聚类,其中,δ为邻域;
3) 计算每个Qij的个数,计算所有相邻Qij之间的关联性,并找出满足条件的Qij.
3.1 需求预测
保证数据分析质量的前提是所选数据具有权威性和客观性,本次实验所选的数据是易车网在2012年1月份某品牌车的数据集,客户的点击量为9 882 039,满足条件的浏览时间为1 232 178,销量为76 663.计算得出点击量与浏览时间均满足条件的个数为84 245,三者同时发生的为销量数,得出客户的点击量和浏览时间与客户的需求量存在91%的关联度,说明客户的点击量与浏览时间量对客户需求量的解释能力很强,从而可以根据下一时期的有效点击量预测出未来的销量.
3.2 客户最佳配送时间预测
随机抽取10个用户的一周位置数据进行分析,由于配送的实际时间关系,只考虑用户10∶00~19∶00的位置数据,数据信息如表2所示.
表2 客户一周位置数据
Tab.2 Location data of customers in a week
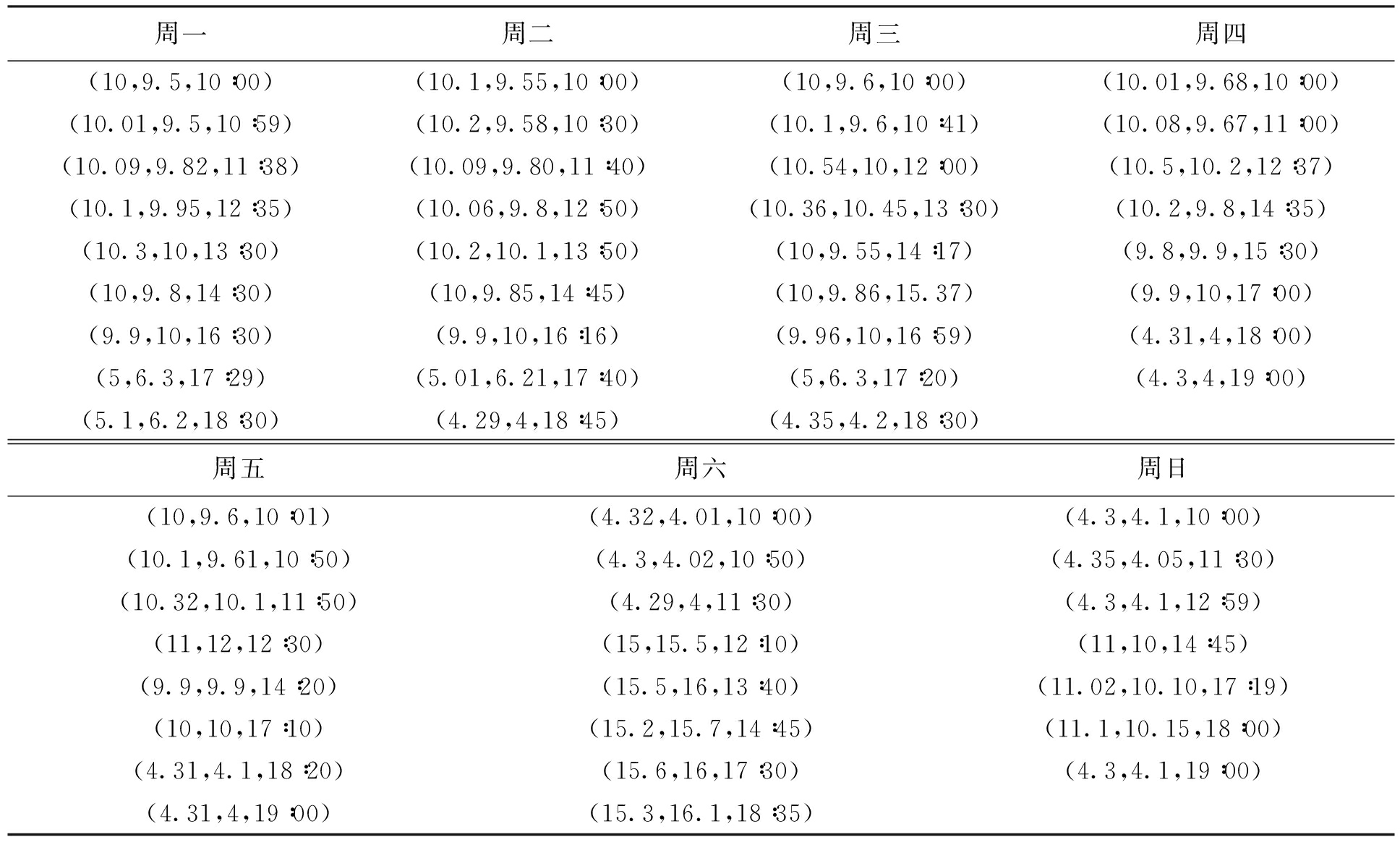
对用户一周的数据进行分段处理后结果如表3所示,di表示第i天.由数据挖掘结果可以得出,Q11和Q12,Q12和Q13之间的关联性要高于其他数据间的关联性,所以选择这两个时间段来配送将提高用户的便捷性.由于用户订单会有配送地址,所以选择离用户配送地址较近的时间段进行配送.将数据语义化,Q11表示用户所在的公司,Q12表示附近的超市,Q13表示住址,如果用户填的订单地址为家庭住址,那么选择Q12和Q13之间的时间段,则输出的时间为Q12,配送时间要在Q12之前到达,而由以上数据可以得出时间tj为17∶20.将预测结果与客户期望的最佳配送时间进行比较可知,预测的配送时间能满足客户可接受的时间.10位客户的最佳配送时间分别为17∶20,17∶20,17∶35,17∶40,18∶10,17∶30,18∶20,18∶10,18∶15,18∶00.
3.3 物流服务供应链仿真
算例中有8个功能提供配送商,客户价格敏感系数都设为1,a0为90%,T(A∩B)为12,客户数量为10,服务水平的敏感参数依次为0.9,0.9,0.7,0.75,1,0.7,0.75,0.85,0.8,0.7.物流服务成本系数η为0.8,功能提供商参加服务的最小利润依次为106、100、101、100、102、100、99、103元,功能提供商的最大服务量xi依次为50、50、55、60、60、60、65、50,惩罚系数π为0.002,产品的价格ci均为100元,不同的功能提供商对不同的任务服务水平也不同,客户和功能提供商的数据如表4~6所示.
表3 客户分段后的位置数据
Tab.3 Location data of customers after segmentation

表4 功能提供商的服务水平
Tab.4 Service level of functional logistics service providers
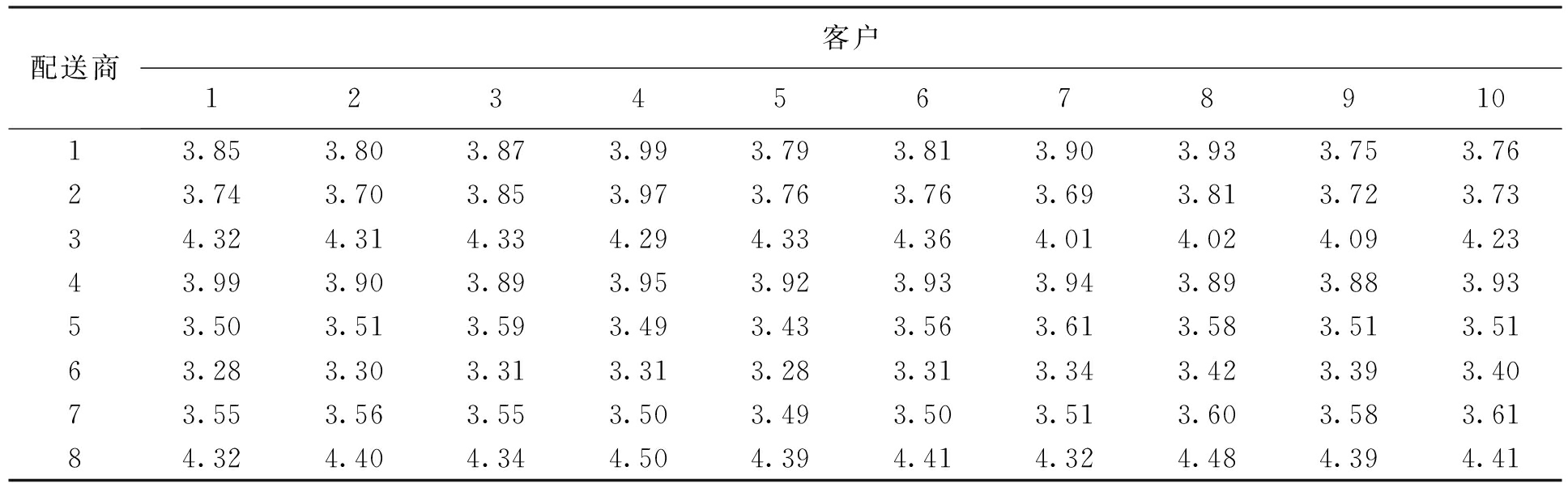
表5 功能提供商的服务报价
Tab.5 Service price of functional logistics service providers 元
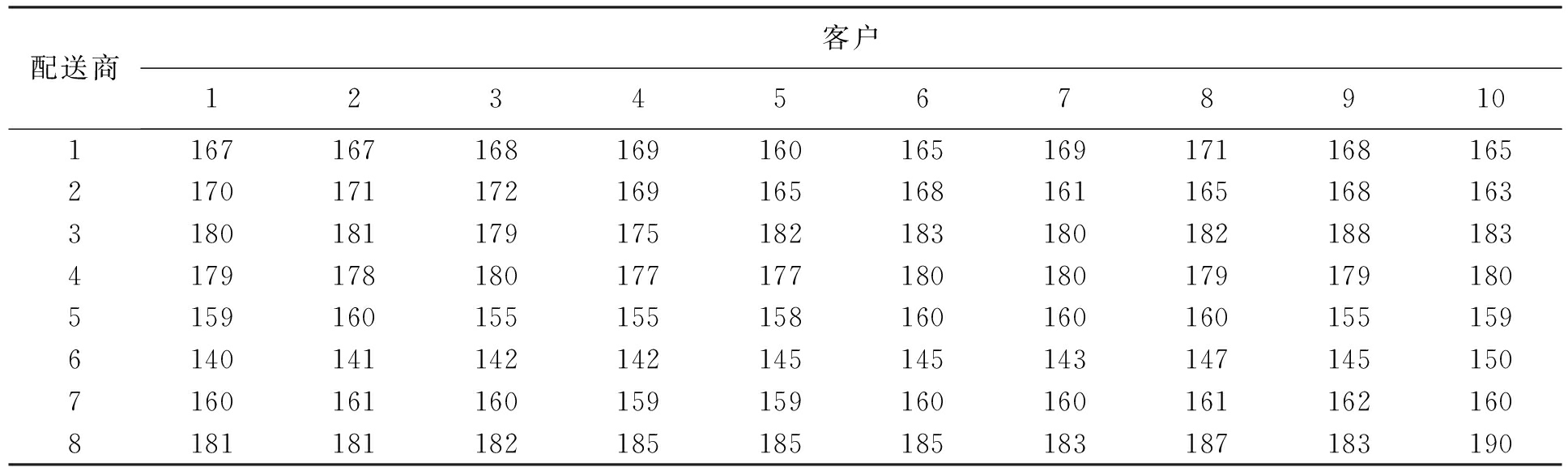
表6 客户可接受的最高价格与期望的服务水平
Tab.6 Highest price accepted by customers and desired service level

计算选出任务分别是功能提供商3为客户1、2服务,功能提供商6为客户3、4、6、7、8、10服务,功能提供商8为客户5、9服务.与实际配送时间t比较,功能提供商3和8的配送时间均满足条件,而功能提供商6对客户3、4、6分别迟到20、10、30 min,最后得出物流服务成本的运行结果为580.78元(计算误差精度为0.01).
本文在大数据背景下,结合客户的点击率和浏览时间的数量预测客户近期的需求,将随机环境下的需求转变为固定需求以便于求解,而大数据的实时性又能满足客户需求的变化.根据客户的位置数据来分析客户的行为规律,从而去预测客户最佳的配送时间.基于大数据的结果建立三级物流服务供应链订单任务分配模型,主要考虑了供应商对客户的吸引力、服务水平、物流成本及配送时间的惩罚成本.研究结果表明,在大数据的背景下分析客户的需求及行为规律,能更好地帮助企业了解客户的喜好,从而能为客户提供更好的服务,在保证了客户服务水平的前提下降低成本,从而提高企业的信誉度,有利于企业长久的发展,获得更多的利益.
本文在建立订单任务分配的模型中也存在一些不足,供应商对客户的吸引力仅从服务报价和服务水平两方面来衡量,今后的研究将考虑更多的因素,从而使客户的个性化需求更加精准.大数据分析也刚刚起步,所以在数据挖掘分析方面,考虑关联性的因素较少,今后将加入更多的因素,使数据挖掘的结果更加精准.
参考文献(References):
[1]李姗姗.物流服务供应链订单分配优化及其遗传算法 [J].运筹与管理,2014,23(5):35-37.
(LI Shan-shan.Genetic algorithm to logistics service supply chain order allocation problem [J].Operations Research and Management Science,2014,23(5):35-37.)
[2]高志军,刘伟,范志强,等.考虑交易费用的LSSC订单分配多目标优化模型 [J].系统工程,2013,30(7):35-39.
(GAO Zhi-jun,LIU Wei,FAN Zhi-qiang,et al.Multi-objective optimization model of order allocation of LSSC considering transaction costs [J].Systems Engineering,2013,30(7):35-39.)
[3]刘伟华,曲思源,钟石泉.随机环境下的三级物流服务供应链任务分配 [J].计算机制造集成系统,2012,20(7):35-39.
(LIU Wei-hua,QU Si-yuan,ZHONG Shi-quan.Order allocation in three-echelon logistics service supply chain under stochastic environments [J].Computer Internet Manufacturing Systems,2012,20(7):35-39.)
[4]Liu W H,Ge M Y,Xie W H,et al.An order allocation model in logistics service supply chain based on the pre-estimate behavior and competitive-bidding strategy [J].International Journal of Production Research,2014,52(8):2327-2344.
[5]范琛,王效俐,陈瑾,等.信息更新下的物流服务订单分配 [J].同济大学学报(自然科学版),2014,42(9):1452-1457.
(FAN Chen,WANG Xiao-li,CHEN Jin,et al.Service order allocation based on multiobjective dynamic programming [J].Journal of Tongji Unversity(Natural Science),2014,42(9):1452-1457.)
[6]李剑锋,陈世平,易荣华,等.二级物流服务供应链定价及其效率研究 [J].中国管理科学,2013,21(2):84-87.
(LI Jian-feng,CHEN Shi-ping,YI Rong-hua,et al.Research on pricing decisions and efficiency in a two-level logistics service supply chain [J].Chinese Journal of Management Science,2013,21(2):84-87.)
[7]范志强.供应链订单分配优化模型及其模拟退火算法 [J].计算机工程与应用,2012,48(25):28-33.
(FAN Zhi-qiang.Simulated annealing algorithm to supply chain order allocation problem [J].Computer Engineering and Applications,2012,48(25):28-33.)
[8]李天阳,何霆,徐汉川.面向价值的服务供应链运作过程模型 [J].计算机集成制造系统,2015,20(1):235-244.
(LI Tian-yang,HE Ting,XU Han-chuan.Value-oriented operation process model for service supply chain [J].Computer Integrated Manufacturing Systems,2015,20(1):235-244.)
[9]Amin S H,Razmi J,Zhang G.Supplier selection and order allocation based on fuzzy SWOT analysis and fuzzy linear programming [J].Expert Systems with Application,2011,38:334-342.
[10]李阳珍.物流服务供应链的可靠度及其优化研究 [J].统计与决策,2014(5):186-188.
(LI Yang-zhen.Reliability and optimization of logistics service supply chain [J].Statistics and Decision,2014(5):186-188.)
[11]常慧君,单洪,满毅.基于分段、聚类和时许关联分析的用户行为分析 [J].计算机应用研究,2014,31(2):526-532.
(CHANG Hui-jun,SHAN Hong,MAN Yi.User behavior analysis based on segmentation,clustering and timing relationship analysis [J].Application Research of Computers,2014,31(2):526-532.)
[12]王和勇,吴晓桦.关联规则在网络客户评论中的关联分析研究 [J].物流工程与管理,2014,36(2):81-84.
(WANG He-yong,WU Xiao-hua.Research on correlation analysis of customer online reviews on association rules [J].Logistics Engineering and Management,2014,36(2):81-84.)
[13]韩霜,周芳娟,谭智华,等.动态竞争环境下基于客户价值的物流终端设施优化模型 [J].公路交通科技,2013,30(11):144-151.
(HAN Shuang,ZHOU Fang-juan,TAN Zhi-hua,et al.An optimization model of logistics terminal facility based on customer value in dynamic competitive environment [J].Journal of Highway and Transportation Research and Development,2013,30(11):144-151.)
[14]刘艳秋,焦妮,李佳.基于确定网络的多级物流网络优化设计 [J].沈阳工业大学学报,2015,37(1):64-68.
(LIU Yan-qiu,JIAO Ni,LI Jia.Optimazation design of multi-level logistics network based on determined network [J].Journal of Shenyang University Techno-logy,2015,37(1):64-68.)
(责任编辑:景 勇 英文审校:尹淑英)
LIU Yan-qiua,WANG Haoa,ZHANG Yinga,CAI Chaob
(a.School of Science,b.School of Management,Shenyang University of Technology,Shenyang 110870,China)
Abstract:In order to solve the problem that the optimal delivery time and demand of customers in the existing order allocation of multi-level logistics service supply chain are not fully considered,under the background of big data,a method to analyze the correlation between the clicks of customers,browsing time of customers and sales and to predict the demand of customers with the knowledge of big data was proposed.In addition,the best delivery time was predicted with the location data of customers.According to the predicting results under the background of big data,an optimization model for the order allocation of three-level logistics service supply chain was established with the objective of minimizing the cost of logistics service integrator,and the model was verified with an example.The results show that the sales and delivery time predicted based on the big data are closer to the actual demand of customers,which can obtain the optimal solutions on the premise of ensuring the service quality for customers.
Key words:three-level logistics service supply chain; big data; order allocation; service level; association rule; user behavior rule; time prediction; demand prediction
收稿日期:2015-08-28.
基金项目:辽宁省科学技术计划资助项目(2013216015);沈阳市科学技术计划资助项目(F14-231-1-24).
作者简介:刘艳秋(1963-),男,吉林四平人,教授,博士生导师,主要从事复杂系统可靠性建模与优化等方面的研究.
doi:10.7688/j.issn.1000-1646.2016.02.13
中图分类号:TP 301
文献标志码:A
文章编号:1000-1646(2016)02-0190-06
*本文已于2015-12-07 16∶18在中国知网优先数字出版.网络出版地址:http://www.cnki.net/kcms/detail/21.1189.T.20151207.1618.022.html