张福勇,赵铁柱
(东莞理工学院 计算机学院,广东 东莞 523808)
摘 要:针对恶意代码,尤其是顽固、隐匿的未知恶意代码危害日益加剧的问题,提出一种基于肯定选择分类算法的恶意代码检测方法.将样本文件转换成十六进制格式,提取样本文件的所有n-gram,计算具有最大信息增益的N个n-gram的词频,并做归一化处理,采用改进的肯定选择分类算法进行分类.该方法保留了肯定选择分类算法高分类准确率的优点,优化了分类器训练过程,提高了训练和检测效率.结果表明,该方法的检测效果优于朴素贝叶斯、贝叶斯网络、支持向量机和C4.5决策树等算法.
关 键 词:网络与信息安全;入侵检测;恶意代码;恶意代码检测;肯定选择分类算法;机器学习;特征选择;静态分析
恶意代码,尤其是顽固、隐匿的未知恶意代码的危害日益加剧[1],吸引了大批工业界和学术界的科研人员对其进行检测研究.针对恶意代码的静态自动分析方法和动态自动分析方法是目前的研究热点.
静态分析方法指在不执行二进制程序的情况下,对样本的静态特征和功能进行分析[2].常见的静态分析方法有:基于静态行为的系统调用序列分析方法[3],基于抽象语义的恶意代码分析方法[4],提取样本文件的n-gram字节特征的检测方法[5-6]及通过挖掘PE文件静态格式信息实现恶意代码检测的方法[7]等.
动态行为分析方法主要是对代码运行过程中系统基本属性、系统调用、I/O请求、控制流、网络行为、寄存器值及内存中变量值的变化等几个方面进行监控,进而分析恶意代码的行为.常见的动态分析方法有:基于系统基本属性的分析方法[8],基于动态行为的系统调用序列分析方法[9],基于IRP序列的检测方法[10],基于控制流的检测方法[11],基于网络行为的检测方法[12],基于寄存器值及内存中变量值变化的检测方法[13-15]及静态特征和动态特征相结合的检测方法[16]等.
恶意代码的自动分析检测方法虽然近年有了长足的发展,但依然存在一些缺陷,对恶意代码实时检测的研究还不够成熟,还需要更多创新性的工作[17].
本文提出一种基于肯定选择分类算法恶意代码检测方法,该方法提取样本文件具有最大信息增益的N个n-gram字节,计算每1 000字节中每个n-gram的词频,并做归一化处理,得到一个N维特征向量,然后,采用改进的肯定选择分类算法判断其类别.实验结果表明,该方法可实现恶意代码的快速准确检测.
基于n-gram字节的恶意代码检测方法[5]已经被广泛采用,且取得了较好的检测效果.目前采用最广泛的基于n-gram字节的检测方法是Jeremy等人[5]提出的,该方法提取样本文件信息增益最大的N个n-gram作为特征数据.检测时,逐一判断待测文件中是否存在N个n-gram中的某一个,如果存在则将对应属性值置为1,否则置为0,最终得到一个N维的特征向量.然后,选用合适的分类算法进行类别判断,这种方法最终得到的是N维特征向量,向量中属性的取值为0或1.而仅包含0和1的数据并不利于分类算法学习得到最佳的分类器,因此,考虑在提取的具有最大信息增益的N个n-gram的基础上,计算每个n-gram的词频,并对词频数据做归一化处理,这样得到的特征数据就不再是仅有0和1的数据,而是取值范围在[0,1]的数据,这样的数据更有利于分类算法的学习和样本的识别.特征向量生成算法如下:
1) 提取样本文件的所有n-gram,这里的n-gram指的是将样本文件转成十六进制后的连续n个字节.假设n=4,一个样本文件转成十六进制后的字节序列为:4D 5A 90 00 03 00,则该文件的所有n-gram为:4D5A9000、5A900003、90000300.
2) 计算所有n-gram的信息增益,并提取具有最大信息增益的N个n-gram.
3) 针对具有最大信息增益的N个n-gram,计算样本文件中包含的每个n-gram的数量,并除以样本文件长度,不足1 kB按1 kB处理.例如,一个样本文件长度为1 124 B,则其表示的文件长度为2 kB,最终得到的是一个N维向量,向量属性值为样本文件每1 kB包含的n-gram数量.
4) 对步骤3)得到的N维向量做归一化处理,处理后的N维向量中属性的取值范围为[0,1].例如,取N=5,最后得到的N维向量形式为:0.012 085、0.024 169、0.048 338、0.012 085、0.012 085.
肯定选择分类算法(positive selection classification algorithm,PSCA)[18-19]是基于人工免疫系统中肯定选择原理和克隆选择原理提出的一种分类算法,该算法在一些基准数据集上测试取得了很好的实验结果.但其在选择最优分类器时采用克隆选择原理,导致算法训练时间过长,而经过大量实验发现,克隆选择原理在选择最优分类器时帮助并不大,为了保证恶意代码检测的高时效性,本文对肯定选择分类算法进行了一些改进,去除了不必要的克隆选择过程,并优化了算法实现流程,确保在不降低分类准确率的前提下,进一步提高分类效率.下面给出改进后算法中用到的符号定义:
D:样本集;
d:样本数据,d∈D;
da:d的属性向量;
dai:da的第i个属性值;
df:d的识别标志;
mc:样本中的类别个数;
Di:第i个类别的样本集,Di⊆D,D={D1∪D2∪…∪Dmc};
C:分类器集合;
Ci:第i个类别的分类器集合,Ci⊆C,C={C1∪C2∪…∪Cmc};
c:分类器,c∈C;
ca:c的属性向量;
cr:c的识别半径(如果d到c的距离小于cr,则认为c能够识别d,本文的距离采用欧几里得距离公式计算);
cs:c的识别值(cs指仅被分类器c识别的样本数);
chs:c的半识别值(chs指同时被分类器c和至少一个其它分类器识别的样本数).
2.1 学习过程
学习过程分别对每个类别的样本进行学习,将正在学习的该类别样本作为自体,其它类别的样本作为非自体,最终训练得到各个类别样本的分类器.学习过程的符号定义及相关函数描述如下:
S:自体样本集,S=Di;
![]() :自体样本的个数;
:自体样本的个数;
s:自体样本,s∈S;
SN:非自体样本集,SN={D1∪D2∪…∪Di-1∪Di+1∪…∪Dmc};
sn:非自体样本,sn∈SN;
distSort(S,SN):将S中每个自体样本到SN中所有非自体样本距离的最小值,按从大到小进行排序;
![]() 经过distSort(S,SN)排序后的自体样本集;
经过distSort(S,SN)排序后的自体样本集;
getClassifier(s,S,SN):生成一个分类器,且该分类器类别与s相同;
setRadius(c,SN):设置cr的值;
setStimulation(c,S):设置cs和chs的值;
recognize(c,s):如果s到c的距离小于cr,返回true;否则,返回false.
改进的肯定选择分类算法的学习过程见算法1.
算法1.学习过程
for each Di(S) in D
Ci←Ø;
distSort(S,SN);
distant[k].f←flase;
end for
if distant[i].f←false
c←getClassifier(distant[i],S,SN);
Ci←Ci∪c;
end if
if recognize(c,distant [j])
distant [j].f←true;
end if
end for
end for
end for
学习过程首先计算每一个自体样本s到所有非自体样本sn距离的最小值,并根据这些值按由大到小的顺序,将自体样本集S进行排序,并将这些样本标示为未识别.然后,选择第一个未被识别的自体样本作为分类器,并设置该分类器的属性值、识别半径、识别值及半识别值,同时将此分类器识别的自体样本标识为已识别,再选择下一个未识别的自体样本作为分类器,如此循环,直到所有自体样本都被识别.
算法2描述了函数getClassifier(s,S,SN)的详细过程,其中识别半径的设置函数setRadius(c,SN)计算公式为
cr=minDist_c(c,SN)α
(4)
式中:minDist_c(c,SN)指分类器c到SN中所有非自体样本距离的最小值;α为识别半径控制参数,α∈(0,1).
算法2.getClassifier(s,S,SN)
ca←s;
cr←setRadius(c,SN);
c←setStimulation(c,S);
return c;
算法3描述了分类器识别值和半识别值设置函数setStimulation(c,S)的具体过程.
算法3.setStimulation(c,S)
cs←0;
chs←0;
for each s in S
if recognize(c,s)←true
if chs←chs+1;
else cs←cs+1;
end if
end if
end for
return c;
2.2 分类过程
分类过程的处理方式与文献[18]中的方法一致,对于分类过程中出现重叠的情况,采用临时移动分类器至两分类器相切的位置.对孔洞的处理采用k最近邻算法,并选择k=3.分类过程的处理流程为:
1) 选择一个测试样本,用学习过程生成的分类器进行识别.
2) 若只有一个类别的分类器识别此样本,则确定此样本类别为识别它的分类器类别,转步骤1);若出现重叠情况,转步骤3);若出现孔洞情况,转步骤4).
3) 重叠情况的识别过程.
4) 孔洞情况的识别过程.
3.1 实验数据集
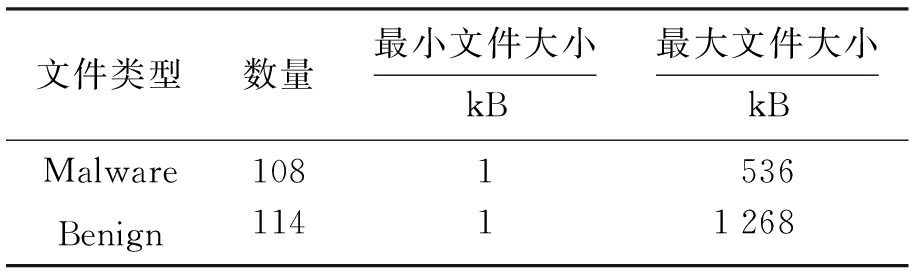
实验中用到的样本文件信息如表1所示.其中,恶意代码样本108个,正常文件样本114个,均为Win32 PE格式.
表1 实验数据
Tab.1 Experimental data
3.2 检测器半径控制参数α的敏感性分析
本节随机选择了恶意代码样本88个,正常文件样本83个来分析参数α取不同值时对分类结果的影响.采用10折交叉验证进行测试,图1显示了α取值范围为0.05~0.95时的分类准确率情况.从图1可以看出,α的取值对分类准确率的影响不大,得到分类准确率的范围为98.25%~99.42%,其中0.05≤α≤0.45时,可以得到最优结果.
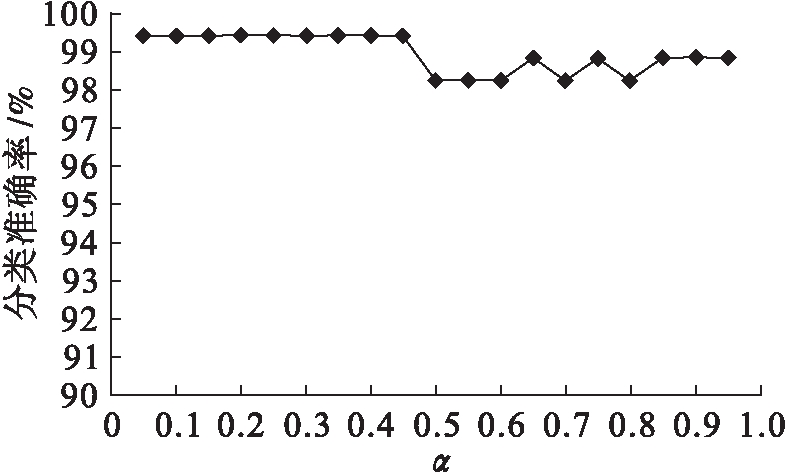
图1 α对分类准确率的影响
Fig.1 Effect of α on classification accuracy
3.3 实验结果比较与分析
前期研究中,测试了N取值为2,3,4,5,6,7,8,9,10,15,20,50等数据,n取值为1,2,3,4等数据的各种组合形式,发现N取值为5,n取值为3时可得到最佳的检测结果.因此,本文实验中N和n取值分别为5和3,即提取最大信息增益的前5个3-gram字节生成特征向量,并将本文算法与朴素贝叶斯(Naïve Bayes,NB)、贝叶斯网络(Bayesian Networks,BN)、支持向量机(Support Vector Machine,SVM)和C4.5决策树(C4.5 Decision Tree,DT)4种分类算法进行比较.这4种分类算法方法均采用WEKA平台,4种方法分别采用WEKA的NaïveBayes、BayesNet、SMO和J48实现.
实验中信息增益的计算以3.2节的171个样本文件为依据,并比较从这171个样本中提取的检测结果,实验结果如表2所示,所有结果均为10折交叉验证的结果.本文方法的结果为α取0.05,0.1,0.15,…,0.9,0.95,19个数据实验结果的平均值,其他4种方法的实验结果均采用WEKA平台的默认参数.
表2 实验结果
Tab.2 Experimental results %

从表2可以看出,本文方法得到的分类准确率最高,并且拥有最低的误检率(FP).对恶意代码的检测率(TP)方面,本文方法与BayesNet最高均为96.3%,但BayesNet的FP高于本文方法.C4.5和Naïve Bayes两种方法的FP稍高,检测结果不理想.值得注意的是SVM方法在实验中获得了100%的TP,但同时FP也高达26.3%,说明SVM方法不适用于该类特征的分类.
实验结果表明,本文提出的基于肯定选择分类算法的恶意代码检测方法具有较好的检测结果,而且所需提取的特征数量少,可实现对恶意代码的快速准确检测.
针对当前恶意代码数量大、检测难的现状,本文提出一种基于肯定选择算法的恶意代码检测方法.该方法从训练样本中提取5个具有最大信息增益的3-gram字节,并通过计算3-gram词频的方式生成特征向量,实现了较高的恶意代码检测率和较低的误检率,并且该方法仅需对少量样本的学习即可实现对未知恶意代码的准确识别,是一种高效的检测方法.
参考文献(References):
[1]360互联网安全中心.2012年中国互联网安全报告[EB/OL].北京:360互联网安全中心,2013(2013-02-25) [2015-04-30].http://awuvsvkkjf.l5.yunpan.cn/lk/QUPZKyLbVTBTH.
(360 Internet Security Center.2012 China’s internet security report [EB/OL].Beijing:360 Internet Secu-rity Center,2013(2013-02-25) [2015-04-30].http://awuvsvkkjf.l5.yunpan.cn/lk/QUPZKyLbVTBTH.)
[2]李鹏,王汝传,武宁.基于空间关系特征的未知恶意代码自动检测技术研究 [J].计算机研究与发展,2012,49(5):949-957.
(LI Peng,WANG Ru-chuan,WU Ning.Research on unknown malicious code automatic detection based on space relevance features [J].Journal of Computer Research and Development,2012,49(5):949-957.)
[3]Ding Y X,Yuan X B,Tang K,et al.A fast malware detection algorithm based on objective-oriented associa-tion mining [J].Computers & Security,2013,39:315-324.
[4]Silvio C,Yang X,Zhou W L.Control flow-based malware variant detection [J].IEEE Transactions on Dependable and Secure Computing,2014,11(4):304-317.
[5]Kolter J Z,Marcus A.Learning to detect malicious executables in the wild [C]//Knowledge Discovery and Data Mining.New York,USA,2004:470-478.
[6]Nissim N,Robert M,Lior R,et al.Novel active learning methods for enhanced PC malware detection in windows OS [J].Expert Systems with Applications,2014,41(13):5843-5857.
[7]Bai J R,Wang J F,Zou G Z.A malware detection scheme based on mining format information [J].The Scientific World Journal,2014,15(2):1-11.
[8]Zhang M,Anand R,Niraj K.A defense framework against malware and vulnerability exploits [J].International Journal of Information Security,2014,13(5):439-452.
[9]Forrest S,Hofmeyr S,Somayaji T.A sense of self for unix processes [C]//IEEE Symposium on Security and Privacy.Berlin,German,1996:120-128.
[10]张福勇,齐德昱,胡镜林.终身学习的否定选择算法 [J].沈阳工业大学学报,2012,34(3):393-397.
(ZHANG Fu-yong,QI De-yu,HU Jing-lin.Negative selection algorithm for life-long learning [J].Journal of Shenyang University of Technology,2012,34(3):393-397.)
[11]Shahid A,Nigel R.A framework for metamorphic malware analysis and real-time detection [J].Computers & Security,2015,48:212-233.
[12]Prakash M C,Lei L,Sabyasachi S.Combining supervised and unsupervised learning for zero-day malware detection [C]//32nd IEEE INFOCOM Conference.Turin,Italy,2013:2022-2030.
[13]Shahzad F,Shahzad M,Farooq M.In-execution dynamic malware analysis and detection by mining information in process control blocks of Linux OS [J].Information Sciences,2013,231:45-63.
[14]Mahboobe G,Ashkan S,Zahra S.Dynamic malware detection using registers values set analysis [C]//9th International ISC Conference on Information Security and Cryptology(ISCISC).Tabriz,Iran,2012:54-59.
[15]Nguyen V,Nguyen T C,Cao D T.Semantic set analysis for malware detection [C]//13th IFIP TC8 International Conference on Computer Information Systems and Industrial Management Applications(CISIM).Hochi Minh,Vietnam,2014:688-700.
[16]Rafiqul I,Lynn M.Classification of malware based on integrated static and dynamic features [J].Journal of Network and Computer Applications,2013,36(2):646-656.
[17]赵刚,宫义山,王大力.考虑成本与要素关系的信息安全风险分析模型 [J].沈阳工业大学报,2015,37(1):69-74.
(ZHAO Gang,GONG Yi-shan,WANG Da-li.Information security risk analysis model considering costs and factors relevance [J].Journal of Shenyang University of Technology,2015,37(1):69-74.)
[18]张福勇.面向恶意代码检测的人工免疫算法研究 [D].广州:华南理工大学,2012:58-77.
(ZHANG Fu-yong.Research on artificial immune algorithms on malware detection [D].Guangzhou:South China University of Technology,2012:58-77.)
[19]Zhang F Y,Qi D Y.A positive selection algorithm for classification [J].Journal of Computational Information Systems,2012,8(1):207-215.
(责任编辑:景 勇 英文审校:尹淑英)
ZHANG Fu-yong,ZHAO Tie-zhu
(Computer Institute,Dongguan University of Technology,Dongguan 523808,China)
Abstract:In order to solve the problem that the harm of malware,especially the persistent and stealthy unknown malware becomes more serious,a malware detection method based on positive selection classification algorithm was proposed.The sample files were converted into hexadecimal format,and all n-grams of sample files were extracted.The word frequency of N n-grams with maximum information-gain was calculated and normalized.The improved positive selection classification algorithm was used to perform the classification.The present method retains the high classification accuracy of positive selection classification algorithm,optimizes the training process of classifier,and improves the efficiency of training and detection.The results reveal that the detection efficiency of the present method is prior to that of such algorithms as Naïve Bayes,Bayesian Networks,support vector machine and C4.5 decision tree.
Key words:network and information security; intrusion detection; malware; malware detection; positive selection classification algorithm; machine learning; feature selection; static analysis
收稿日期:2015-06-15.
基金项目:国家自然科学基金资助项目(61402106);广东省教育科学规划资助项目(14JXN029).
作者简介:张福勇(1982-),男,山东龙口人,讲师,博士,主要从事网络与信息安全等方面的研究.
doi:10.7688/j.issn.1000-1646.2016.02.16
中图分类号:TP 309
文献标志码:A
文章编号:1000-1646(2016)02-0206-05
*本文已于2015-09-15 00∶01在中国知网优先数字出版.网络出版地址:http://www.cnki.net/kcms/detail/21.1189.T.20150915.0001.008.html