杨品林
(大连艺术学院 文化艺术管理学院,辽宁 大连 116600)
摘 要:针对由于彩色图像数据特征较多使得目标特征挖掘容易出现不确定性的问题,提出一种新的彩色图像数据库中目标特征数据挖掘方法.采用减法聚类算法对彩色图像数据进行聚类,采用离群点检测技术对聚类数据进行分类处理,采用量子行为粒子群优化方法选取最优目标图像特征数据,并与结构相似度计算方法相结合,实现对最优目标图像特征数据的挖掘.结果证明,该方法相比传统的挖掘方法,其挖掘召回率降低了约17%,挖掘精确度提高了约28.6%.
关 键 词:彩色图像;数据库;目标特征;数据挖掘;数据聚类;相似度计算;离群点检测;粒子群优化
近年来,由于计算机性能的不断提高,使得计算机视觉与数据挖掘技术不断进步[1-2].随着彩色成像技术及设备的不断改进,彩色图像应用越来越广泛,彩色图像数据愈来愈大,数据库规模增长速度过快,而且彩色图像特征众多,导致彩色图像数据库目标图像特征挖掘效率降低[3-4].对目标特征数据进行准确挖掘,是增加彩色图像数据库使用效率最有效的方法之一,成为了该领域亟待解决的问题,受到了学者的广泛关注[5-6].
文献[7]提出基于数据融合的特征数据挖掘方法,该方法利用空间数据的挖掘理论和方法,从彩色图像数据库中提取出有规律性的潜在有用信息、数据关系等,自动抽取出目标图像特征,该方法虽能对彩色图像数据库中的目标特征数据进行挖掘,但需要进行反复迭代计算;文献[8]提出基于关联规则的特征数据挖掘方法,通过图像纹理特征联合关联规则对目标特征进行表征,再根据模板统计挖掘方法提取出目标特征,该方法能够较好地表达目标特征,并进行特征挖掘,但存在目标特征量多,挖掘时间较长的缺点;文献[9]提出基于支持向量机的目标特征数据挖掘方法,该方法针对目标特征数据集的特点,有针对性地进行特征数据挖掘,但忽略了周围环境对数据产生的干扰,存在图像数据挖掘抗干扰能力差的问题.
针对上述问题,本文提出一种新的目标特征数据挖掘方法,首先采用减法聚类方法处理彩色图像数据,然后利用离群点检测技术聚类数据,采用量子行为粒子群优化方法选取最优的目标图像特征数据,并结合结构相似度计算方法,实现对最优目标图像特征数据的挖掘.
本文采用减法聚类方法对彩色图像数据库中的目标特征数据进行聚类,为划分目标特征数据提供基础条件[10-12].
假设有M个样本的目标图像特征数据,新到达样本的权值记为qj(t),j=1,2,…,Nt;聚类权值记为pi(t-1),i=1,2,…,C.将Nt个数据样本划分成为C个聚类中心,每个聚类中心表示为
![]()
(1)
式中,μij为样本属于聚类中心的模糊隶属度,1≤i≤C,1≤j≤Nt.
设有n个d维的目标特征数据集X=(x1,x2,…,xn),对于数据集X里的每个目标特征数据xi可计算出其密度指标Di,计算表达式为
![]()
(2)
式中,ra为目标图像特征数据xi的领域半径.密度指标最高的数据记为x1,且与聚类中心相对应的密度指标记作D1.若xk为第k次选出的聚类中心,Dk为其密度指标,则需要对目标图像特征数据的密度指标进行修正[13-14],修正表达式为
![]()
(3)
式中,rb为密度指标函数显著减少的领域半径.选择密度指标最高的目标图像特征数据xk+1作为新的聚类中心,其密度指标为Dk+1,则在满足Dk+1/D1<ε约束条件下,完成对目标图像的聚类,其中,0<ε<1,为事先给出的阈值.ε的大小直接与聚类效果有关,ε越小,聚类效果越好.
采用量子行为粒子群优化方法对上述分类的目标图像特征数据进行选择,计算步骤如下:
1) 初始化粒子种群,获取粒子位置.种群中每个粒子位置均是一个可行解,都是由目标图像特征数据属性组成,粒子位置表达式为
Si=[w11,w12,…,w1k,wn1,wn2,…,wnk,
b1,b2,…,bk]
(4)
式中,w1k,wnk,bk分别为数据的横、纵及侧向坐标.
2) 对每一个粒子,采用基本ELM算法计算出相应的权值,然后估算出它的自适应函数值.
3) 获取更新粒子个体最优位置,更新表达式为
(5)
式中,f()为适应值函数.
4) 对任意粒子i,将其个体最优位置的适应值和全局最优位置的适应值进行对比,获取全局最优位置,即
(6)
5) 根据获取的最优位置对目标图像特征数据进行选择,当pg(t)最大时,其目标图像特征数据属性最显著;若pg(t)最小时,其数据属性不显著,可直接忽略.
当目标图像特征数据的个数为card(Vd),其中,Vd为决策值域,且数据集中对象Θ在各个等效类中随机分布,则Θ包含的目标图像特征数据信息量为
![]()
(7)
式中,p(Θi)为对象被正确分类到Θi的概率.Θ相对于属性a的条件熵为
![]()
(8)
式中,p(vj)为属性a具有属性vj的概率.在目标图像特征数据a属性已知的情况下,Θ仍然存在不确定性,随着目标信息熵的下降,其数据信息不确定性也会增加.当目标图像特征数据属性Gi含有m个属性,则目标图像特征数据属性组Gi的条件信息熵为
![]()
(9)
式中,p(Gi|va1,va2,…,vam)为Gi的联合条件概率.目标图像特征数据集Gi与数据对象Θ之间的互信息量为
I(Θ,Gi)=H(Θ)-H(Θ|Gi)
(10)
I(Θ,Gi)主要反映了目标图像特征数据属性Gi对Θ的不确定性消除程度.若I(Θ,Gi)值较大,说明目标图像特征数据集Gi为最优目标图像特征数据;反之,若I(Θ,Gi)值较小,则目标图像特征数据集Gi为较差目标图像特征数据,可根据I(Θ,Gi)值的大小进行顺序挖掘.
在确定I(Θ,Gi)值的基础上,采用结构相似度计算方法对目标图像特征数据进行挖掘,则数据相似度获取表达式为
(11)
式中:Ei为样本总量;pi为目标图像特征数据在数据集中的概率.
综上所述,在满足目标数据选择要求的基础上,通过确定目标图像特征数据信息熵,结合结构相似度计算方法,可对彩色图像数据库中的目标图像特征数据进行挖掘.
为了充分验证本文提出方法的有效性,实验采用数据库SQL Server2000中的目标特征数据,共选取了50个样本约26 480个目标特征数据.实验参数设置如表1所示.
表1实验参数设置
Tab.1Settingofexperimentalparameters

在目标特征数据量一定的情况下,采用改进的挖掘方法与基于信息融合的特征数据挖掘方法、基于关联规则的特征数据挖掘方法进行对比,目标特征数据挖掘召回率的对比分析结果如图1所示.目标特征数据挖掘精确度的对比分析结果如图2所示.
召回率是检索出的相关数据数量和数据库中所有相关数据数量的比值,可以对检索系统的查全率进行衡量[15-17].由图1可知,采用基于信息融合的特征数据挖掘方法时,其平均召回率约为58%,在初始阶段其召回率即急剧增加,虽然其在40 s之后增速变慢,但是其整体召回率仍为最高;采用基于关联规则的特征数据挖掘方法时,其平均召回率约为46%,在0~30 s时召回率要比其它方法的高,但其后期增长速度变缓,使得整体召回率较低;采用改进的挖掘方法时,平均召回率约为29%,且在30 s之后开始下降,稳定性较强,具有一定的优势.
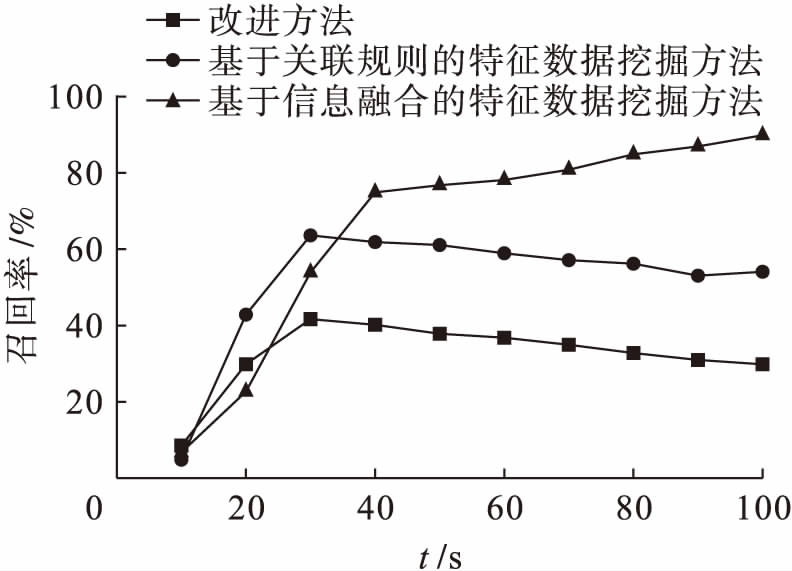
图1不同方法的召回率对比
Fig.1Comparisonresultsofrecallratefordifferentmethods
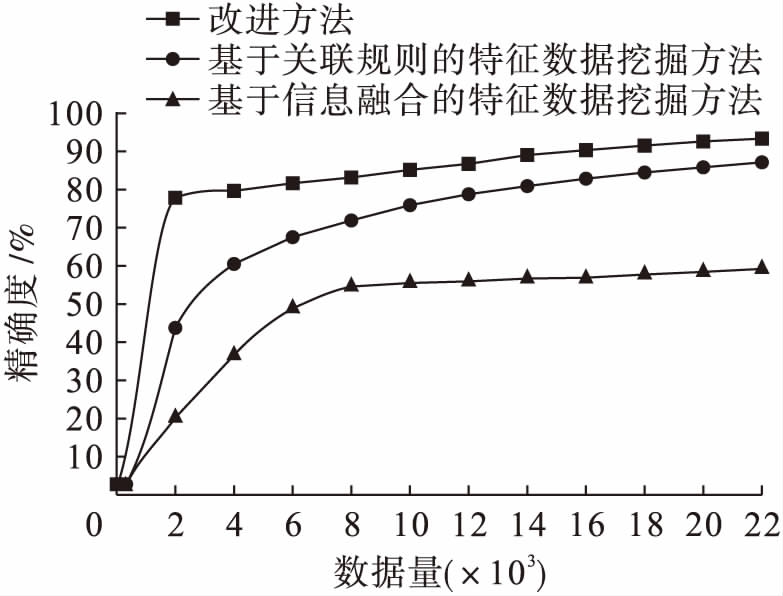
图2不同方法的挖掘精确度对比
Fig.2Comparisoninminingaccuracyunderdifferentalgorithms
由图2可知,采用基于信息融合的特征数据挖掘方法时,其稳定挖掘精确度约为50.5%,但初始阶段其挖掘准确率较低,不适合少量数据的挖掘;采用基于关联规则的特征数据挖掘方法时,其平均精确度为64.8%;采用改进的挖掘方法时,其平均精确度为83.4%,且在挖掘初期精确度已提高到了80%以上,并且随着数据量的增加,精确度也随之增加.
为了进一步验证本文提出方法的有效性,对三种方法执行代价进行比较,在数据量逐渐增加的情况下,三种方法挖掘过程运行代价如图3所示.
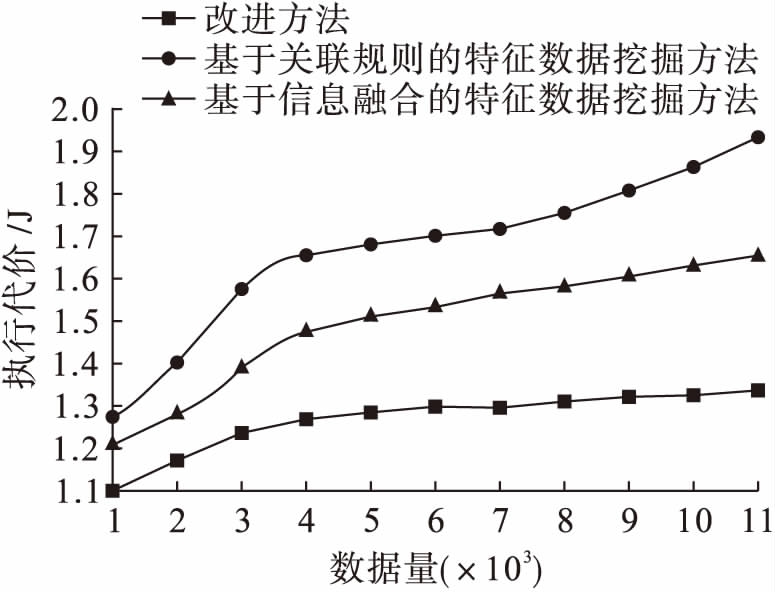
图3不同方法执行代价比较结果
Fig.3Comparisonresultsinexecutingcostofdifferentmethods
执行代价即挖掘方法对目标特征数据进行挖掘时所耗费的能量,执行代价越高,挖掘所需的能量则越高.由图3分析可知,在新增数据量不断增多的情况下,三种方法执行代价均逐渐增多,但和基于关联规则的特征数据挖掘方法与基于信息融合的特征数据挖掘方法相比,本文方法执行代价曲线增加幅度明显较低,说明本文方法挖掘所需能耗较少,效率最高.
针对目标特征数据挖掘方法存在的挖掘效果差的问题,提出基于量子行为粒子群优化方法与结构相似度计算方法相结合的数据挖掘方法.实验对比发现,采用改进的挖掘方法时,其整体召回率与挖掘精度均好于其他方法,且在新增数据量相同的情况下,执行代价最小,效率最高.本文所提出算法更适用于数据量大,挖掘精度要求高的工况.
参考文献(References):
[1] 李炳乾.对等P2P网络中大数据关键特征挖掘模型仿真 [J].计算机仿真,2014,31(11):294-296.
(LI Bing-qian.Model simulation of big data key characteristics mining for Peer-to-Peer networks [J].Computer Simulation,2014,31(11):294-296.)
[2] 胡文瑜,孙志挥,吴英杰.数据挖掘取样方法研究 [J].计算机研究与发展,2011,48(1):45-54.
(HU Wen-yu,SUN Zhi-hui,WU Ying-jie.Study of sampling methods on data mining and stream mining [J].Journal of Computer Research and Development,2011,48(1):45-54.)
[3] 汤恒耀,胡志华.基于链距离估计的非显著特征数据挖掘算法 [J].科技通报,2015,31(6):142-144.
(TANG Heng-yao,HU Zhi-hua.Non significant features data mining algorithm based on chain distance dstimation [J].Bulletin of Science and Technology,2015,31(6):142-144.)
[4] 武靖娜,杨姝,王剑辉.一种分布式大数据挖掘的快速在线学习算法 [J].沈阳师范大学学报(自然科学版),2016,34(1):100-104.
(WU Jing-na,YANG Shu,WANG Jian-hui.A new fast online learning algorithm based on distributed mining of big data [J].Journal of Shenyang Normal University(Natural Science Edition),2016,34(1):100-104.)
[5] 李骏骁.多层差异网络深度入侵数据挖掘方法研究 [J].计算机仿真,2015,32(4):235-238.
(LI Jun-xiao.Multilayer network intrusion data mining depth difference method research [J].Computer Simulation,2015,32(4):235-238.)
[6] 康凤,蒋小惠,冯梅.网络伪装隐形文本特征检测及数据挖掘方法 [J].科技通报,2014,30(4):113-115.
(KANG Feng,JIANG Xiao-hui,FENG Mei.Method of data mining and hidden text data feature detection for network intrusion [J].Bulletin of Science and Technology,2014,30(4):113-115.)
[7] 米晓萍,李雪梅.基于信息融合度传递的频域徙动入侵特征挖掘算法 [J].计算机科学,2015,42(3):224-227.
(MI Xiao-ping,LI Xue-mei.Mining algorithm of frequency domain migration intrusion feature based on information fusion transfer [J].Computer Science,2015,42(3):224-227.)
[8] 陈佳,胡波,左小清,等.利用手机定位数据的用户特征挖掘 [J].武汉大学学报(信息科学版),2014,39(6):734-738.
(CHEN Jia,HU Bo,ZUO Xiao-qing,et al.Personal profile mining based on mobile phone location data [J].Geomatics and Information Science of Wuhan University,2014,39(6):734-738.)
[9] 陈向东,李平.基于色彩特征的CAMSHIFT视频图像汽车流量检测 [J].沈阳工业大学学报,2015,37(2):183-188.
(CHEN Xiang-dong,LI Ping.Vehicle flow detection with CAMSHIFT video images based on color feature [J].Journal of Shenyang University of Technology,2015,37(2):183-188.)
[10]马瑞,周谢,彭舟,等.考虑气温因素的负荷特性统计指标关联特征数据挖掘 [J].中国电机工程学报,2015,35(1):43-51.
(MA Rui,ZHOU Xie,PENG Zhou,et al.Data mining on correlation feature of load characteristics statistical indexes considering temperature [J].Proceedings of the CSEE,2015,35(1):43-51.)
[11]王小平.基于运动背景的自适应视频对象分割算法 [J].重庆邮电大学学报(自然科学版),2016,28(1):95-99.
(WANG Xiao-ping.Adaptive video object segmentation algorithm based on background motion [J].Journal of Chongqing University of Posts and Telecommunications (Nature Science Edition),2016,28(1):95-99.)
[12]黄斌,许舒人,蒲卫.基于MapReduce的数据挖掘平台设计与实现 [J].计算机工程与设计,2013,34(2):495-501.
(HUANG Bin,XU Shu-ren,PU Wei.Design and implementation of MapReduce-based data mining platform [J].Computer Engineering and Design,2013,34(2):495-501.)
[13]余旺盛,田孝华,侯志强.基于区域边缘统计的图像特征描述新方法 [J].计算机学报,2014,37(6):1398-1410.
(YU Wang-sheng,TIAN Xiao-hua,HOU Zhi-qiang.A new image feature descriptor based on region edge statistical [J].Chninese Journal of Computers,2014,37(6):1398-1410.)
[14] 柯丹丹,蔡光程,曹倩倩.基于图像特征的各向异性扩散去噪方法 [J].计算机应用,2012,32(3) :742-745.
(KE Dan-dan,CAI Guang-cheng ,CAO Qian-qian.Anisotropic diffusion denoising method based on image feature [J].Journal of Computer Applications,2012,32(3) :742-745.)
[15]朱阅岸,周烜,张延松,等.多核处理器下事务型数据库性能优化技术综述 [J].计算机学报,2015,38(9):1865-1879.
(ZHU Yue-an,ZHOU Xuan,ZHANG Yan-song,et al.A survey of optimization methods for transactional daabase in multi-core era [J].Chninese Journal of Computers,2015,38(9):1865-1879.)
[16] 陆会明,周钊,廖常斌.基于实时数据库系统的历史数据处理 [J].电力自动化设备,2009,29(3):127-131.
(LU Hui-ming ,ZHOU Zhao ,LIAO Chang-bin.Historical data processing in real-time database system [J].Electric Power Automation Equipment,2009,29(3):127-131.)
[17]刘伟,孟小峰,凌妍妍.一种基于图模型的Web数据库采样方法 [J].软件学报,2008,19(2):179-193.
(LIU Wei,MENG Xiao-feng,LING Yan-yan.A graph-based approach for web database sampling [J].Journal of Software,2008,19(2):179-193.)
YANG Pin-lin
(School of Culture and Art Management, Dalian Art College, Dalian 116600, China)
Abstract:Aiming at the problem that the uncertainty caused by the multiple features of color image data is easy to appear in the object feature mining, a new mining method for the target feature data in the color image database was proposed.The color image data were clustered with the subtractive clustering method, and the clustered data were classified with the outlier detection technique.In addition, the optimal target image feature data were selected with the quantum behaved particle swarm optimization method.In combination with the structural similarity calculation method, the mining of optimal target image feature data was realized.The results show that compared with the traditional mining method, the recall rate of proposed method reduces by about 17%, while the mining accuracy increases by about 28.6%.
Key words:color image; database; target characteristic; data mining; data clustering; similarity calculation; outlier detection; particle swarm optimization
收稿日期:2016-07-15.
基金项目:辽宁省教育厅科学研究项目(W2012283,W2010114);辽宁省职业技术教育学会科研规划项目(lzy15148,lzy15531).
作者简介:杨品林(1979-),男,辽宁大连人,副教授,硕士,主要从事计算机网络与数据库应用等方面的研究.
* 本文已于2017-10-25 21∶12在中国知网优先数字出版.网络出版地址:http://kns.cnki.net/kcms/detail/21.1189.T.20171025.2112.010.html
doi:10.7688/j.issn.1000-1646.2018.01.11
中图分类号:TP 311.13
文献标志码:A
文章编号:1000-1646(2018)01-0060-05
(责任编辑:景 勇 英文审校:尹淑英)