费贤举1,李 虹2,田国忠1
(1.常州工学院 计算机信息工程学院,江苏 常州 213032;2.吉林省质检检测基地 吉林省纤维检验处,长春 130103)
摘 要:针对数据挖掘过程中数据聚类操作的初始聚类数目和初始聚类中心确定困难的问题,提出了一种软子空间结合竞争合并机制的模糊加权聚类算法.通过对软子空间聚类算法的目标函数进行改写,并结合数据簇势的大小对各数据簇进行竞争与合并操作,实现了对数据的聚类处理.结果表明,该算法能够准确地对数据样本进行聚类,并且聚类结果与初始数据簇数目和初始聚类中心无关,能够满足对高维数据聚类处理的需要,具有较好的实际应用价值.
关 键 词:数据挖掘;数据聚类;特征加权;软子空间聚类;竞争合并机制;模糊聚类算法;聚类中心;聚类数目
信息时代中人们时刻都面临着各种类型的数据,这些数据对生产生活具有重要影响.随着技术的发展,数据信息成指数级快速增长.如何利用这些数据,如何在数据中发现所需信息成为当前的研究热点.数据挖掘技术[1-6]作为海量数据处理的有效手段,越来越受到人们的重视.数据挖掘通过分析并处理特定类型的数据,发现其中包含的潜在规律,辅助人们做出正确的决策.数据挖掘分为数据准备、信息挖掘和结果解释三个步骤.信息挖掘通过处理数据来发现其内部包含的规律信息或潜在价值,是数据挖掘的重点.信息挖掘的方法包括监督学习、关联分析、聚类分析和特征选择及提取[7-12]等.聚类分析是指利用特定技术手段发现数据的内在规律,并按照规律将数据进行科学分类.聚类分析是数据挖掘的重要方法和关键过程,直接影响数据挖掘的最终结果,是当前数据挖掘领域的重点研究内容之一.
软子空间聚类算法是聚类分析算法的重要组成部分.软子空间聚类算法通过给数据的不同特征赋予加权系数来区分特征之间的重要性,实现对聚类结果的灵活控制.影响软子空间聚类算法效果的关键因素包括数据簇数目和初始聚类中心两个方面.优秀的聚类算法要能够收敛到合理的聚类数目并且聚类中心的初始选择对聚类结果影响较小.目前流行的聚类方法包括数据簇评估准则法、聚类可视化法和模糊聚类法等.这些方法虽然能够得到合理的聚类数目,但是对数据各方面特征的考虑还不全面.本文在软子空间聚类算法的基础上引入竞争合并机制,提出了一种软子空间结合竞争合并机制的模糊加权聚类算法,结合了软子空间算法和竞争合并机制的优点,实现了可靠聚类到合理数目和初始化聚类中心不影响聚类结果的目标.
软子空间聚类算法也称为特征加权聚类算法,是指在数据的处理过程中为每个数据簇的特征赋予加权系数来标记特征的重要性.基于竞争合并机制的模糊聚类算法利用正则化项来使各个聚类中心竞争合并,最后得到满足要求的聚类数目.将软子空间聚类算法与竞争合并的模糊聚类算法相结合,可以得到软子空间结合竞争合并机制的模糊加权聚类算法的目标函数,即
(1)
式中:xjk为数据集;vik为聚类中心;uij为模糊隶属度;wik为特征加权系数;m为模糊加权指数;α为正则项系数;c为聚类中心数;n为数据样本数目;d为特征数目.上述参数满足![]()
式(1)中前半部分用于计算各数据点到聚类中心的模糊加权距离和,后半部分计算各数据簇的势平方和.当聚类中心数为n时,前半部分最小;当聚类中心数为1时,后半部分最小.合理选择α并使J最小可得到满足条件的数据簇数和聚类中心位置.利用拉格朗日乘子法原理并采用迭代求解的方法求满足J最小时的vik.根据要求设置初始聚类中心数目c、聚类中心vik、模糊加权指数m和模糊隶属度uij,迭代过程如下所示.
1) 计算聚类中心vik、特征加权系数wik和第i个数据簇的势Ni,其计算公式分别为
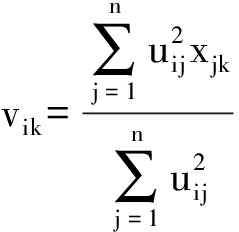
(2)
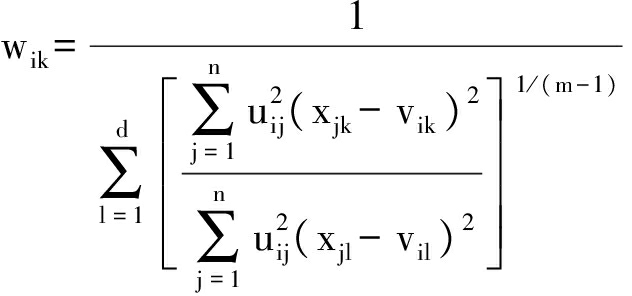
(3)
![]()
(4)
2) 计算正则项系数α.正则项系数用于调节目标函数中前后两部分的比重,需要根据聚类中心和加权系数等参数动态计算,其计算公式为

(5)
式中:t为迭代次数;τ(t)为每次迭代中的学习因子,其计算公式为
τ(t)=τ0exp(-|t-t0|/ζ)
(6)
其中:τ0为学习因子初始值;t0和ζ为根据实际情况选择的常量.
3) 计算模糊隶属度uij,其计算公式为
![]()
(7)
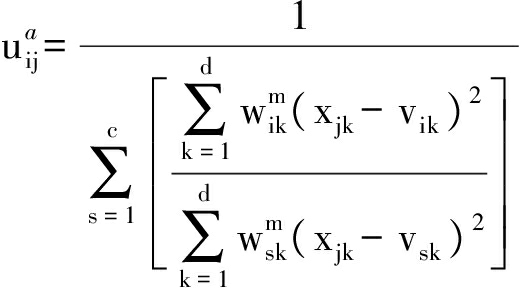
(8)

(9)
式中:![]() 为样本到聚类中心的特征加权距离;
为样本到聚类中心的特征加权距离;![]() 用于削减计算过程中出现的虚假聚类中心的势;
用于削减计算过程中出现的虚假聚类中心的势;![]() 为单个样本对数据簇的势的平均加权,其计算公式为
为单个样本对数据簇的势的平均加权,其计算公式为
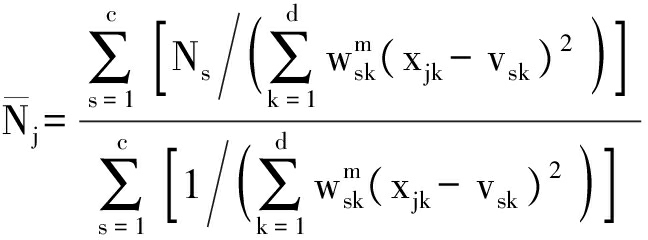
(10)
4) 计算数据簇势的阈值MT和各个聚类中心之间的距离D,并求出距离D的最小值Dmin.当某个数据簇的势Ni小于阈值MT时,就消去该数据簇.当Dmin满足式(12)时,合并距离为Dmin的两个数据簇.MT公式和判别条件分别为
![]()
(11)
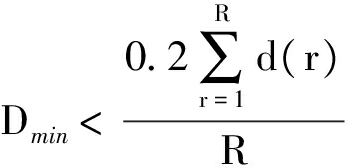
(12)
式中:η为合并阈值参数;c(t)为t次迭代时的聚类中心数;d(r)为两个聚类中心之间的距离数值;R为各个聚类中心之间的距离数据总数,其表达式为
![]()
(13)
5) 根据削减和合并结果调整聚类中心数目c,当聚类中心数目保持稳定或满足迭代结束条件时停止计算,所得的vik即为所需的聚类中心结果,否则返回步骤1)继续执行.
为了直观地观察算法处理结果,在二维空间中产生3类高斯分布数据作为算法处理的数据集,验证算法是否能够实现可靠聚类及聚类的性能.3类数据的真实聚类中心分别为(20,60)、(40,40)、(60,20),每类数据包括100个数据点,3类数据的协方差矩阵分别为![]() 和
和![]()
假设初始聚类中心数为15,学习因子初始值τ0为0.7,时间常量t0和ζ分别为10和15,合并阈值参数η为0.75,模糊加权指数m为3.数据点、真实聚类中心和初始聚类中心如图1所示.
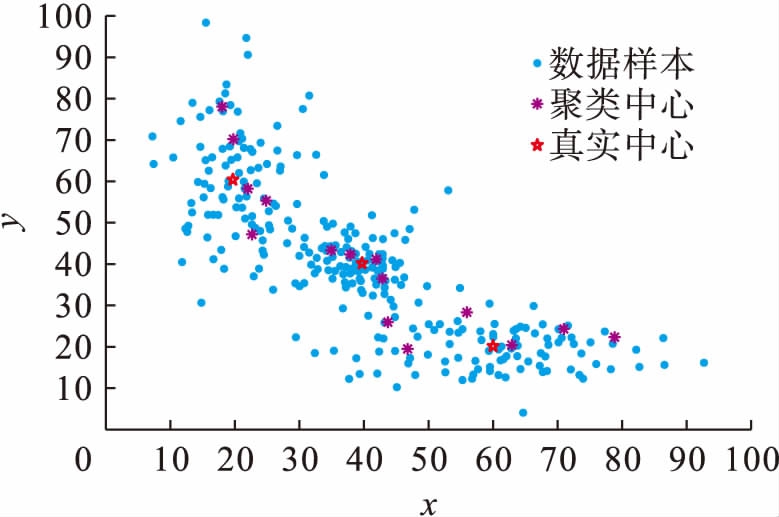
图1数据点及聚类中心分布
Fig.1Datapointsanddistributionofclusteringcenter
迭代运算多次后,聚类结果如图2所示.其中,图2a表示2次迭代后,15个初始聚类中心还剩下10个;图2b表示5次迭代后,聚类中心还剩下6个;图2c表示9次迭代后,聚类中心还剩下5个;图2d表示12次迭代后,聚类中心还剩下3个,在之后的迭代运算中聚类中心数目不再改变.由图2可知,在迭代过程中,聚类中心的数目不断减少,并且各个聚类中心的位置也在不断变化.最后剩下的3个聚类中心的坐标已经非常接近各自的真实聚类中心,因此,该算法有比较好的聚类效果和聚类准确性.
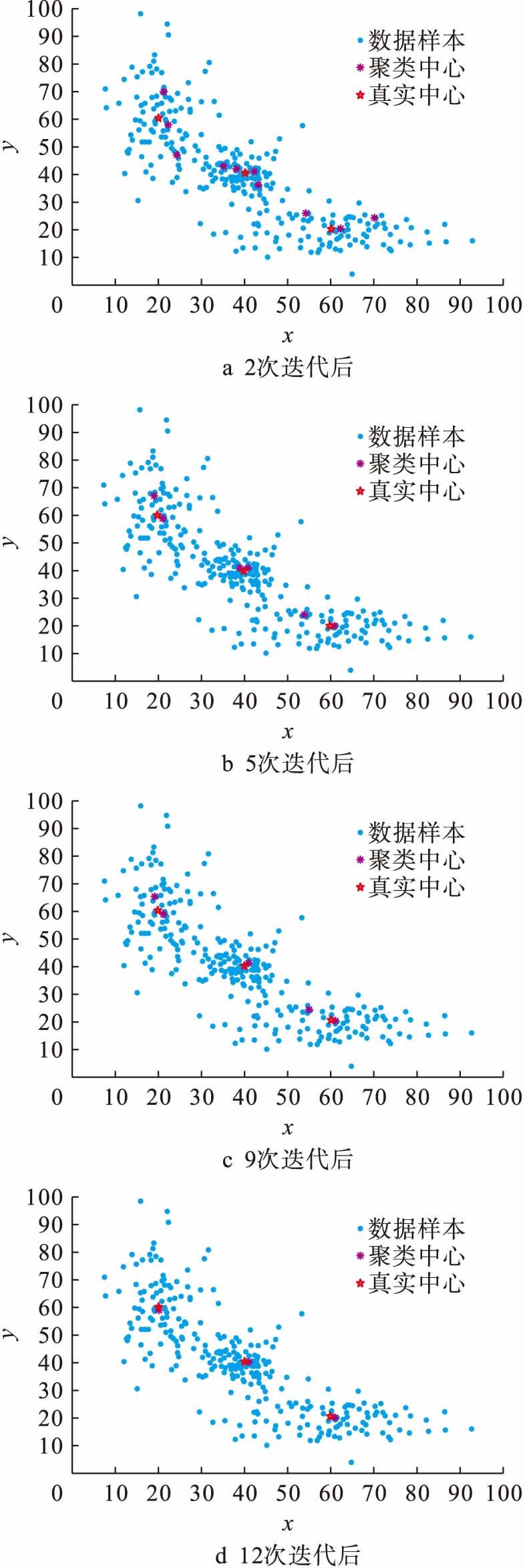
图2聚类结果
Fig.2Clusteringresults
分别设置5组不同的真实聚类中心进行试验.每组数据的产生方法与前述试验相同,即指定相应的聚类中心,根据不同的协方差矩阵产生随机的数据样本.采用互信息指标作为评价聚类准确性的指标.互信息指标通过计算聚类结果与实际分类进行匹配后的平均互信息大小来标记正确分类的准确度,其计算公式为
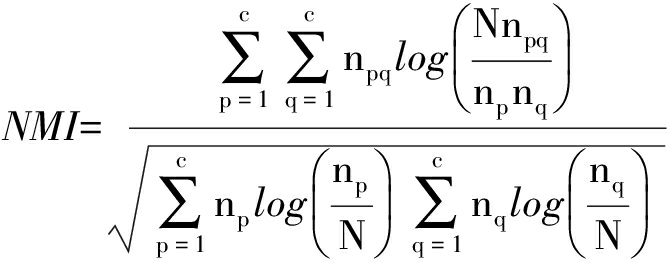
(14)
式中:npq为真实类为p而被分为聚类结果q的数据个数;np为聚类结果为p的数据个数;nq为真实类为q的数据个数;N为总的数据个数.不同真实聚类中心NMI如表1所示.
表1聚类处理互信息指标数据表
Tab.1Mutualinformationindexdatatableinclusteroperation
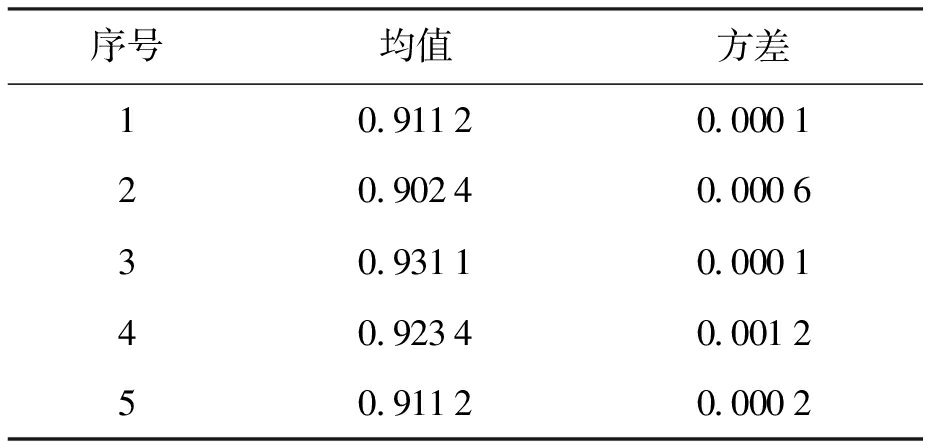
由表1可知,聚类算法对数据聚类的准确度较高,且聚类结果不受真实聚类中心影响,因此,该算法能够在各种情况下实现对数据样本的可靠聚类.
分别选择不同的初始聚类中心数进行运算,迭代过程中聚类中心数的变化情况如图3所示.由图3可知,虽然选择的初始聚类中心数不同,迭代过程中聚类中心数目在不断下降.经过若干次迭代后,聚类中心数目都稳定于3.因此,聚类算法对初始聚类中心数目变化不敏感,能够可靠地收敛到合理的聚类中心数.
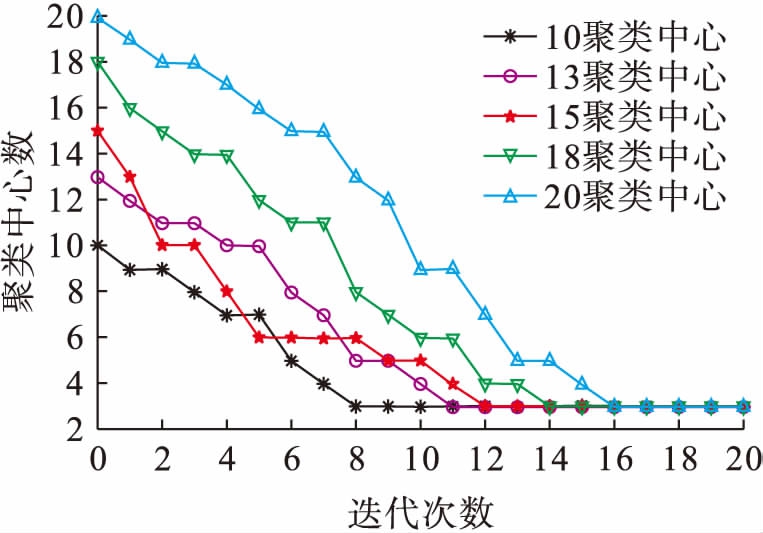
图3运算过程中聚类中心数
Fig.3Numberofclusteringcenterinoperationprocess
随机选择15个初始聚类中心位置进行6次聚类处理,每次迭代过程中聚类中心数的减少情况如图4所示.由图4可知,在初始聚类中心不同时,经过若干次运算后聚类中心数目都稳定于3.因此,聚类算法对初始聚类中心位置的选择不敏感,任意选择初始聚类中心位置都能够保证可靠地收敛于真实聚类中心.
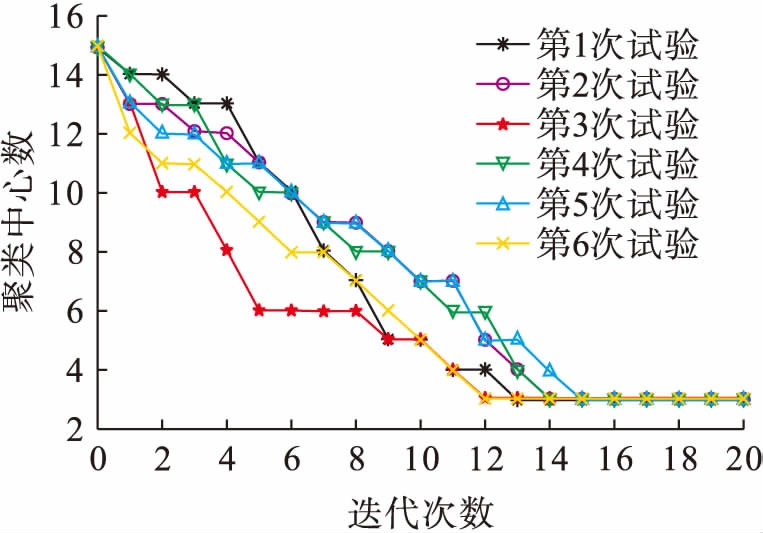
图4聚类处理过程中聚类中心数
Fig.4Numberofclusteringcenterinoperationprocess
本文结合软子空间聚类算法和基于竞争合并机制的模糊聚类算法,提出了一种软子空间结合竞争合并机制的模糊加权聚类算法.该算法通过对软子空间聚类算法的目标函数进行修改,使其具备了软子空间聚类算法和竞争合并机制模糊聚类算法的优点.求解过程通过迭代的方式运行,能够根据实际需要控制运算的速度和精度.结果表明,该算法能够以较高的准确度实现对数据样本的聚类分析,运算结果与初始数据簇的个数和初始聚类中心的位置无关,具有比较广泛的适用性.
参考文献(References):
[1] 任艳.微信息大数据粗糙集的近似约简 [J].沈阳工业大学学报,2016,38(3):309-313.
(REN Yan.Approximate reduction of micro-message big data rough set [J].Journal of Shenyang University of Technology,2016,38(3):309-313.)
[2] 刘城霞.基于MS关联规则数据挖掘模型的应用与探讨 [J].计算机技术与发展,2013,23(1):25-28.
(LIU Cheng-xia.Application and discussion of data mining model based on microsoft association rules algorithm [J].Computer Technology and Development,2013,23(1):25-28.)
[3] 张宇献,刘通,董晓,等.基于改进划分系统的模糊聚类有效性函数 [J].沈阳工业大学学报,2014,36(4):431-435.
(ZHANG Yu-xian,LIU Tong,DONG Xiao,et al.Validity function for fuzzy clustering based on improved partition coeffcient [J].Journal of Shenyang University of Technology,2014,36(4):431-435.)
[4] 陈晋音,何辉豪.基于密度的聚类中心自动确定的混合属性数据聚类算法研究 [J].自动化学报,2015,41(10):1798-1813.
(CHEN Jin-yin,HE Hui-hao.Research on density-based clustering algorithm for mixed data with determine cluster centers automatically [J].Acta Automa-tica Sinica,2015,41(10):1798-1813.)
[5] 高志春,陈冠玮,胡光波,等.倾斜因子K均值优化数据聚类及故障诊断研究 [J].计算机与数字工程,2014,42(1):14-18.
(GAO Zhi-chun,CHEN Guan-wei,HU Guang-bo,et al.Fault diagnosis and optimal data clustering based on K-means with slope factor [J].Computer & Digital Engineering,2014,42(1):14-18.)
[6] 刘云霞.基于动态时间规整的面板数据聚类方法研究及应用 [J].统计研究,2016,33(11):93-101.
(LIU Yun-xia.Research and application of panel data clustering method based on dynamic time warping [J].Statistical Research,2016,33(11):93-101.)
[7] 王德青,朱建平,王洁丹.基于自适应权重的函数型数据聚类方法研究 [J].数据统计与管理,2015,34(1):84-92.
(WANG De-qing,ZHU Jian-ping,WANG Jie-dan.Research of clustering analysis for functional data based on adaptive weighting [J].Journal of Applied Statistic and Management,2015,34(1):84-92.)
[8] 李因果,何晓群,李新春.基于Tucker3分解的三路数据聚类方法 [J].数理统计与管理,2016,35(1):71-80.
(LI Yin-guo,HE Xiao-qun,LI Xin-chun.Three-way data clustering method based on tucker3 decomposition [J].Journal of Applied Statistic and Management,2016,35(1):71-80.)
[9] 唐东明.基于Hadoop的仿射传播大数据聚类分析方法 [J].计算机工程与应用,2015,51(4):29-34.
(TANG Dong-ming.Affinity propagation clustering for big data based on Hadoop [J].Computer Engineering and Applications,2015,51(4):29-34.)
[10]孙浩军,闪光辉,高玉龙,等.一种高维混合属性数据聚类算法 [J].计算机工程与应用,2015,51(8):128-133.
(SUN Hao-jun,SHAN Guang-hui,GAO Yu-long,et al.Algorithm for clustering of high-dimensional data mixed with numeric and categorical attributes [J].Computer Engineering and Applications,2015,51(8):128-133.)
[11]马雯雯,邓一贵.新的短文本特征权重计算方法 [J].计算机应用,2013,33(8):2280-2282.
(MA Wen-wen,DENG Yi-gui.New feature weight calculation method for short text [J].Journal of Computer Applications,2013,33(8):2280-2282.)
[12]胡先兵,赵国庆.引入时频聚集交叉项干扰抑制的大数据聚类算法 [J].计算机科学,2016,43(4):197-201.
(HU Xian-bing,ZHAO Guo-qing.Large data clustering algorithm introducing time and frequency clustering interference suppression [J].Computer Science,2016,43(4):197-201.)
FEI Xian-ju1, LI Hong2, TIAN Guo-zhong1
(1.School of Computer Information & Engineering, Changzhou Institute of Technology, Changzhou 213032, China; 2.Office of Fiber Inspection of Jilin Province, Quality Supervision and Inspection Base of Jilin Province, Changchun 130103, China)
Abstract:Aiming at the problem that the initial clustering number and center are difficult to be determined in the data clustering opertion of data mining process, a fuzzy weighting clustering algorithm based on the soft subspace as well as the competition and combination mechanism was proposed.Through rewriting the objective function of soft subspace clustering algorithm and combining the size of data clusters, the competition and combination operation was carried out for the data clusters, and the clustering treatment of data was achieved.The results show that the proposed algorithm can accurately perform the clustering of data samples, and the clustering results are independent on the initial clustering number and center.The algorithm can meet the need in high dimensional data clustering processing and has the great practical value.
Key words:data mining; data clustering; feature weighting; soft subspace clustering; combination and competition mechanism; fuzzy clustering algorithm; clustering center; clustering number
收稿日期:2016-12-16.
基金项目:国家自然科学基金资助项目(61363004).
作者简介:费贤举(1975-),男,安徽合肥人,讲师,硕士,主要从事数据挖掘、智能信息处理和数据可视化等方面的研究.
* 本文已于2017-12-22 15∶21在中国知网优先数字出版.网络出版地址:http://kns.cnki.net/kcms/detail/21.1189.T.20171222.0920.002.html
doi:10.7688/j.issn.1000-1646.2018.01.14
中图分类号:TP 311
文献标志码:A
文章编号:1000-1646(2018)01-0077-05
(责任编辑:钟 媛 英文审校:尹淑英)