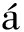 ndez等[6]提出一种基于URL自动化网页分类方案,根据URL模式区分网页类别.
ndez等[6]提出一种基于URL自动化网页分类方案,根据URL模式区分网页类别.秦 鹏1,曹天杰2
(1.六盘水师范学院 计算机科学与信息技术系,贵州 六盘水 553004;2.中国矿业大学 计算机科学与技术学院,江苏 徐州 221116)
摘 要:针对传统网页分类中存在的准确率和查全率不高、分类效率低的情况,提出一种基于朴素贝叶斯分类的网页预分类算法.算法根据用户的网上活动情况提取相关网址,分析网页内容和网页关键词,利用朴素贝叶斯分类算法进行分类,根据用户对各类网页的浏览情况分析用户的行为特征.采用改进的文本权值计算方法,并引进网址预分类机制,提高数据的处理效率以及分类的准确率.结果表明,网址分类算法准确,能够充分发掘用户的兴趣喜好,可以作为用户行为分析的数据算法进行商业推广和司法取证.
关 键 词:网页关键词;朴素贝叶斯;网页分类;行为特征;权值计算方法;网址预分类;商业推广;司法取证
信息化时代网络产生海量数据,针对用户网上行为数据挖掘成为数据分析的一大热点话题.对于公司,可以通过发掘用户行为习惯,推出相应产品;对于社会,通过分析用户数据,可以发现潜在的社会问题,完善相关机制,打击网络犯罪;对于高校,可以分析学生的行为特征,提供个性化网站服务.
国内外众多学者对网页分类进行了积极的探究,金一宁等[1]提出一种基于VSM模型的KNN分类算法,分别对基于标题、正文、正文和链接结合及标题和链接结合的分类结果进行比较;许世明等[2]提出通过预置关键词表进行预分类的方法,极大地提高了分类的速度;江国荐等[3]基于网页半结构化特点,提出了一种基于稀疏自动编码和LBP神经网络的分类器,降低了文本训练时间,网址分类正确率得到了极大提高;代宽[4]等结合网页半结构化特征改进TF-IDF算法,提高了网页的召回率和准确率;国外学者Lee等[5]提出一种简化群优化SSO训练权重的方法,并采用Taguchi方法设置参数,充分发挥单词权重的更新性;Hernndez等[6]提出一种基于URL自动化网页分类方案,根据URL模式区分网页类别.
本文针对中文网页结构和URL特点,改进TF-IDF权值计算方法,并基于朴素贝叶斯分类算法,引进网址预分类机制,提出一种基于朴素贝叶斯的中文网页预分类算法,根据分类结果分析用户的兴趣爱好.
网页分类一般包括网页文本提取、构建文本特征及文本分类三个过程.
要对网页进行分类,首先需要提取网页文本,对网页文本进行预处理,提取body标记中的文本数据、锚文本、Title标记、Meta标记、H1、H2等标记内容[7-8],去除注释标记内容和网页通用内容.
对处理后的文本进行文本分词,得到具有独立信息的载体.文本分词是网页关键词提取和文本分类的基础,本文采用的文本分词算法是在.NET环境中集成中科院的分词技术ICTCLAS,该算法的优点是支持用户词典接口扩展以及分词粒度可调[9].
文本表示方法主要有布尔模型、向量空间模型和统计语言模型,本文主采用向量空间模型VSM来表示具体的页面,向量形式为(ti1,wi1,ti2,wi2,…,tij,wij),其中,tij为页面i的第j个特征词,wij为页面i的第j个特征词的权值[10].
在网页文本分词后,为了减少文本空间的向量维数,需要进行关键词提取,找出能够代表整篇网页主要内容的词语,构建每个网页的文本特征库.
1.2.1 计算词条权重
传统的TF-IDF单词权重计算方法表示为
W=UTFfIDF
(1)
式中:UTF为词频,指单词出现在给定文档中的次数;fIDF为逆向文档频率,是反映单词在文档集中频繁度的重要指标,其计算公式为
fIDF=log2(N/n)
(2)
式中:N为总文档数;n为包含词条的文档数.
在HTML半结构化网页中,不同标记中文本的重要程度不同,传统TF-IDF算法不适用于网页文本权重计算.HTML中存在很多不同的域,比如标题Title、元数据Meta、正文Body,正文中又可分为段标记数据、H标记数据、锚文本数据等.如果词条出现在页面title中,其重要程度最大,因为一篇网页的标题基本上反映其描述的内容,可以为其赋予较高的权值[11].表1中显示了不同标记在文本中的重要程度.
表1标记在页面中的重要性
Tab.1Importanceofsigninpage
根据网页特点,本文将网页文本分为body内容文本和关键特征文本(kff),关键特征词包括标题Title标签,Meta标签中名为keywords和description的元数据,链接文本,H1、H2标记段落文本以及其他一些重要的Html标签域中的文本[12-13],因此词条改进后的权重计算公式为
Wid=∂Wbody+(1-∂)Wkff
(3)
式中,∂为协调因子,0<∂<1,通过调整∂的大小进行试验,找到最优的权重计算方法.正文中词条权重Wbody与关键特征权重Wkff表达式为
Wbody=UTFf
(4)
f=log2(Nm/n)
(5)
![]()
(6)
式中:m为某一类Ci中包含词条的文档数;fik为Wkff在文档中特征域上出现的次数;Wik为Wkff在页面中的重要程度.
1.2.2 选取关键词
计算完词语的权重后,通常可以采取两种方式确定网页的关键词,一种是通过设定关键词权重阀值,权重超过该阀值的即可认为是关键词;另外一种是将词语按照词权重大小逆序排列,选取权重排名靠前的几个词语作为网页关键词[14],本文选择权值靠前的词语作为网页关键词.
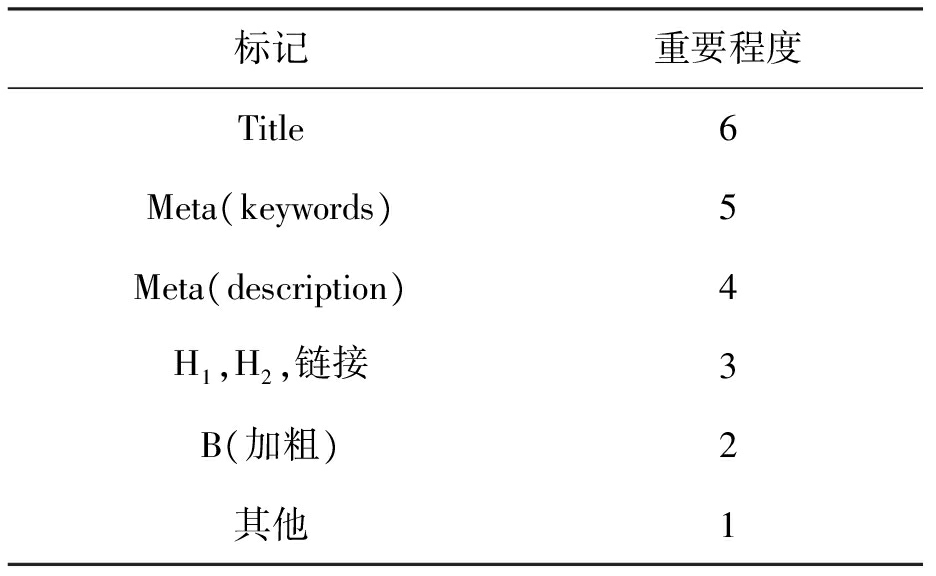
网页分类即是对网页中的文本进行分类,常用的分类方法有基于统计的Bayes分类、KNN、支持向量机、决策树及回归模型等.本文基于朴素贝叶斯分类算法,提出一种改进的预分类算法以提高分类效率.文本分类首先要提取待分类文本的特征项,根据训练文本集构建文本分类器,然后将特征项在分类器中进行分类,输出分类结果[15-16].网页分类系统的一般模型如图1所示.

图1网页分类系统的一般模型
Fig.1Generalmodelforwebpageclassificationsystem
贝叶斯理论是基于统计推断的过程,需要计算一般信息和先验信息,得到后验信息.它的主要特点是利用概率来表示所有不确定的形式,并且利用概率规则来实现学习和推理,通过计算过去某段时间发生的概率来估计将来发生的概率.
贝叶斯分类器是一个简单的基于应用贝叶斯独立假设理论的概率分类器.贝叶斯定理中条件概率和反条件概率之间的关系可表示为
![]()
(7)
式中:P(Y)为Y的先验概率或是边沿概率,即不将X的任何信息考虑在内的概率;P(Y|X)为给定X后,Y的条件概率,它的值来自或是取决于X的值.构建后验概率时,很多情况下需要给定一个数据D,并找到在数据集E中的条件概率P(E|D).假设最大值e包含于E,任何最大可能性的假设均称作最大后验假设,标记为EMAP,即
EMAP=argmaxe∈EP(E|D)=
(8)
朴素贝叶斯分类的实现过程主要包括以下步骤:
1) 计算类的先验概率.数据样本用一个n维的特征向量X表示,用于描述属性对样本的度量,系统中的属性值即为特征词,接着计算每个分类Ci的先验概率P(Ci),即
P(Ci)=Nci/N
(9)
式中,Nci为总样本中属于类Ci的样本数.
2) 计算每个类的条件概率.朴素贝叶斯算法使用独立假设检验,认为属性值相互条件独立,Ci类条件概率为
![]()
(10)
式中:Nxc为Ci类中包含属性x的样本数,系统中Nxc即为在Ci类中包含词条x的样本数;V为样本中总的类别数,即类别C的总数.为了避免极端零值的情况出现,此处对Nxc的值进行加1处理.
3) 计算类后验概率.根据贝叶斯分类理论,将数据样本划分给后验概率较大的类,因此在计算完后验概率后,即可知道网页的分类情况.后验概率计算表达式为
![]()
(11)
对于每一个数据样本,P(X)均一样,因此式(11)可简化为
P(Ci|X)=aP(Ci)P(X|Ci)
(12)
在分析过程中,为了避免计算值较小情况的出现,可以对后验概率进行放大处理,这样方便分类的处理.在此只需要对后验概率值乘以一个整数M即可,最终的后验概率表达式为
P(Ci|X)=aP(Ci)P(X|Ci)M
(13)
完整的基于朴素贝叶斯网页分类流程如图2所示.
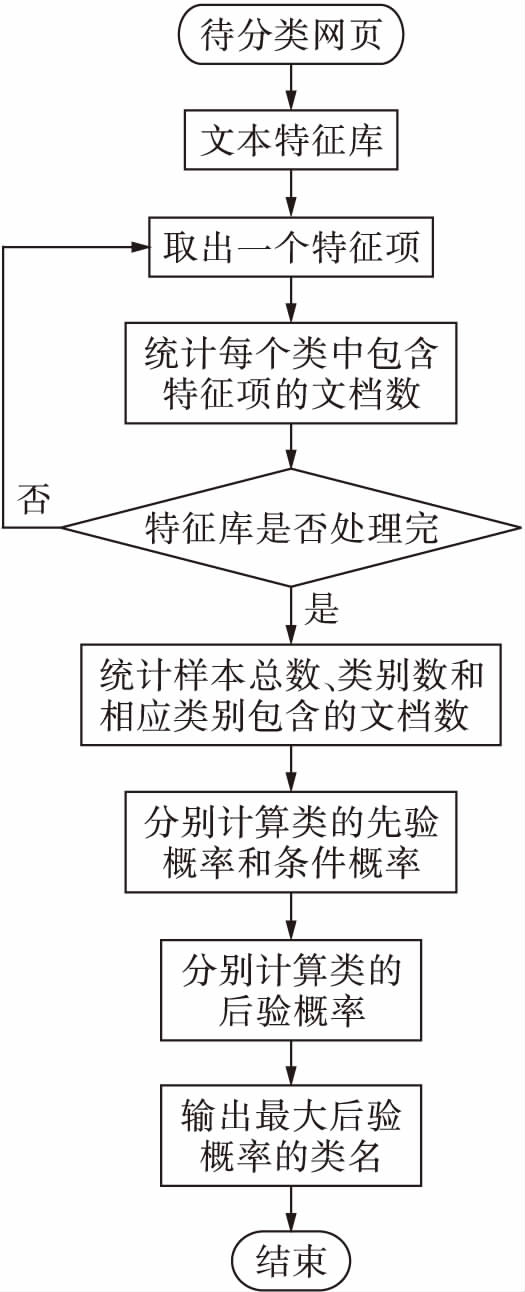
图2网页分类流程图
Fig.2Flowchartofwebpageclassification
在数据计算过程中,为了在较短时间内获取足够多的信息,需要提高计算效率.由于用户浏览的网址较多,缓存文件也很大,如果通过传统的分析方法很难在短时间内获取有效信息.为了提高分类速度,统计用户对每种类别网页的浏览情况,本文针对网页独有的特点,提出一种网页预分类方法.
在网页开发的过程中,网页开发者首先设计的是其首页,然后根据相关功能建立相应的子类网址.一个典型的域名通常包括传输协议、主机类型、主机名、二级域名和顶级域名.其中顶级域名是一个国家独有的,比如中国的顶级域名为cn.二级域名中使用最多的主要有5个,分别是com、org、net、mail、edu,其中com适用于商业公司,org用于非盈利机构,net用于大型网络中心,mail用于军事机构,edu用于教育网站.以学校网址http://www.lpssy.edu.cn为例,其主机名为lpssy,二级域名为edu,顶级域名为cn.
假设网页不受黑客入侵,其网址对应的网页类别是不变的,如上所述,可以先根据顶级域名进行初次划分,再对不同的类别进行判断.如果每次都进行分类则要耗费大量时间,故可以为已经正确分类的网址建立一个哈希表.在对获取的网址进行分类时,首先将获取的网址和已经进行正确分类的网址进行对比,如果该网址与已经存在的网址相同,则直接输出分类结果.如果该网址的主机名存在于已经正确分类的网址中,则直接输出分类结果.如果该网址不存在已经建立的哈希表中,根据顶级域名进行分类,如果分类成功,则直接输出分类结果;否则再根据朴素贝叶斯算法进行具体分类,输出分类结果,其流程图如图3所示.
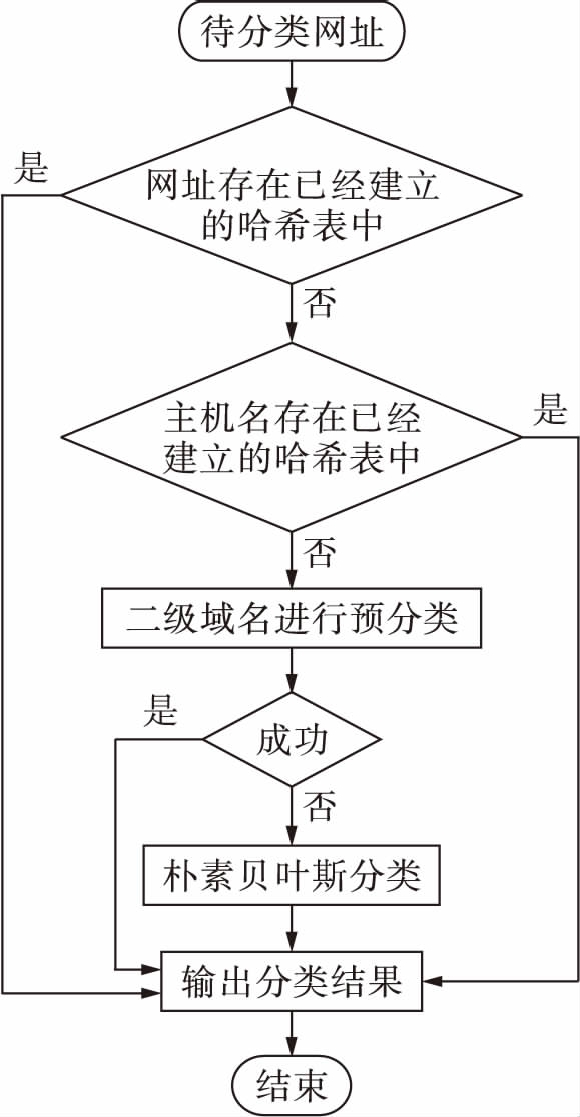
图3预分类的网页分类流程图
Fig.3Flowchartofwebpagepre-classification
在文本分类中,常用于评估参数的指标有3种,分别是分类查全率r、准确率p和F1测试值.其中查全率和准确率可以通过分类混合矩阵来描述,分类混合矩阵中包含了真实的情况和分类器的预测结果.
准确率p和查全率r反映的是分类质量的两个方面,理论上是不相干的,然而实际情况中高准确率通常是在牺牲查全率的情况下获得的,因此,引入评估指标F1测试值,其定义为
![]()
(14)
系统中采用的训练文本集数据为SouGou提供的网页文本集,总类别为10个,分别是文化、邮箱、IT、体育、教育、军事、色情、黑客、音乐及财经.测试数据集为用户浏览网址下载的相关网页文本.
训练集中每一类别的数据采用2 000篇网页文本作为训练集,总的训练集数据为20 000篇网页文本.测试时,每个类别的网页分别采用100篇网址进行测试,总网址为1 000条URL网址.测试效果如表2所示.
表2网页分类测试结果
Tab.2Testingresultsofwebpageclassification
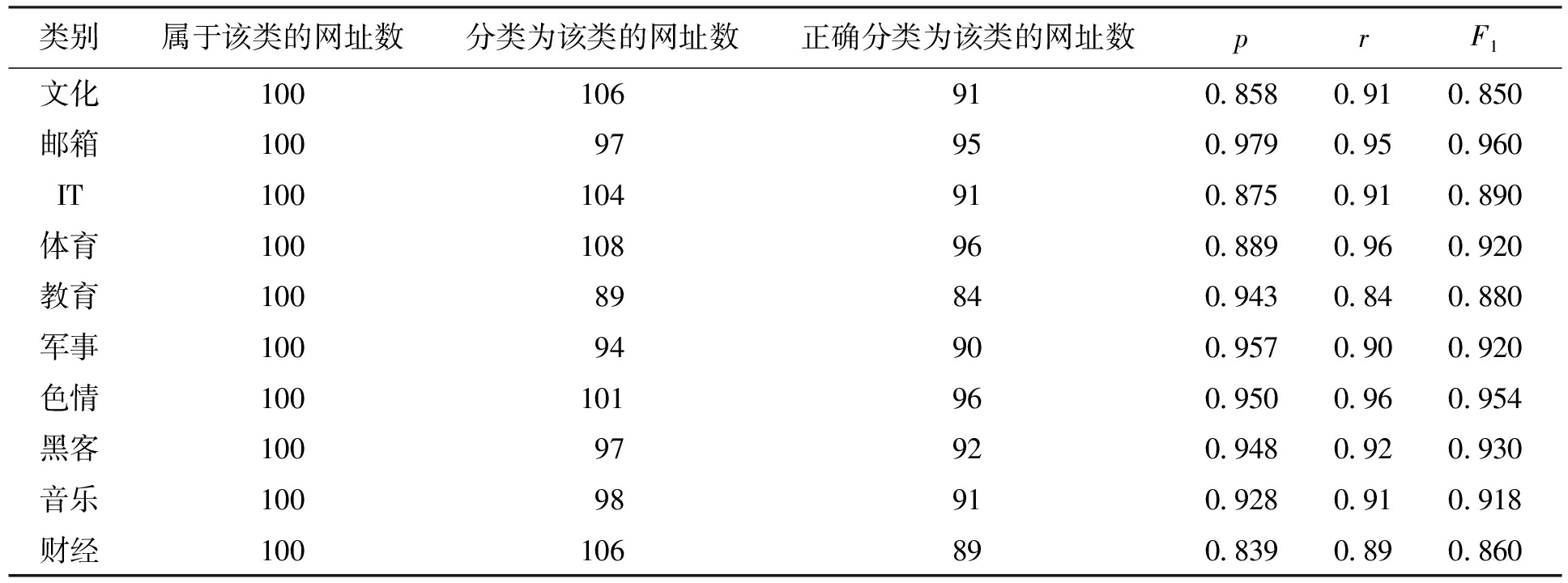
由表2可知,本文采用的网页预分类算法具有很高的准确性,几种类别的F1值均超过了0.85,邮箱、色情、体育、军事、黑客及音乐类F1值都在0.9以上,可以满足分类要求,算法准确率较高,且分类时间较短.
从表2中还可以看出,文化、教育、IT及财经类的分类效果不是很理想,分析其原因可以归结为以下几个方面:
1) 文化、教育类网页题材内容部分重叠,网页关键词代表性不够,导致分类效果不佳;
2) IT类和黑客类区分度不大,黑客类网站中包含很多IT类知识介绍,内容容易混淆,难以区分;
3) 财经类网站特点不明显,内容涉及范围较广,因此分类容易出错.
通过对用户浏览的网址进行分类,统计各类网站的浏览情况,可以分析出用户的行为习惯,如图4所示.从图4中可以看出,目标用户网上活动分布较广,各种页面内容均有涉及,其中对IT和文化类网站浏览数量较多,黑客及色情网站也存在部分浏览量.
本文通过用户的网页浏览记录获取网址内容,进行网页分类,挖掘用户的行为特征.主要创新之处在于:根据网页结构特征提出改进的单词权值计算方法,根据URL特点提出网页预分类算法,二者有机结合在一起,可以快速进行网址分类.该分类算法可以帮助相关法证部门分析犯罪分子心理;也可作为商业服务为用户提供喜欢的网站;还可以在高校中为学生提供个性化服务,具有很强的实用性.
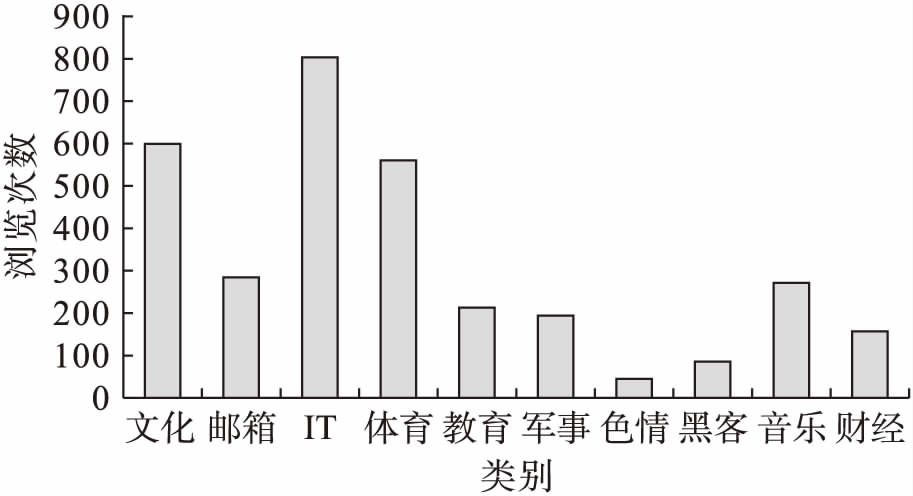
图4用户行为分析
Fig.4Behavioranalysisofuser
参考文献(References):
[1] 金一宁,王华兵,王德峰.基于KNN及相关链接的中文网页分类研究 [J].哈尔滨商业大学学报,2011,27(2):203-206.
(JIN Yi-ning,WANG Hua-bing,WANG De-feng.Research on chinese webpages classification based on k-nearest neighbour algorithm and relative hyperlinks [J].Journal of Harbin University of Commerce,2011,27(2):203-206.)
[2] 许世明,武波,马翠,等.一种基于预分类的高效SVM中文网页分类器 [J].计算机工程与应用,2010,46(1):125-128.
(XU Shi-ming,WU Bo,MA Cui,et al.Efficient SVM chinese web page classifier based on pre-classification [J].Computer Engineering and Applications,2010,46(1):125-128.)
[3] 江国荐,顾乃杰,张旭,等.基于SAE-LBP的网页分类研究 [J].小型微型计算机系统,2016(4):738-742.
(JIANG Guo-jian,GU Nai-jie,ZHANG Xu,et al.Research on webpage classification based on sparse auto-encoder and layer-wise back propagation [J].Journal of Chinese Computer Systems,2016(4):738-742.)
[4] 代宽,赵辉,韩冬,等.基于向量空间模型的中文网页主题特征项抽取 [J].吉林大学学报(信息科学版),2014,32(1):88-94.
(DAI Kuan,ZHAO Hui,HAN Dong,et al.Theme feature extraction of chinese webpage based on vector space model [J].Journal of Jilin University (Information Science Edition),2014,32(1):88-94.)
[5] Lee J H,Yeh W C,Chuang M C.Web page classification based on a simplified swarm optimization [J].Applied Mathematics & Computation,2015,270(3):13-24.
[6] Hern ndez I,Rivero C R,Ruiz D,et al.CALA:An unsupervised URL-based web page classification system [J].Knowledge-Based Systems,2014,57(2):168-180.
ndez I,Rivero C R,Ruiz D,et al.CALA:An unsupervised URL-based web page classification system [J].Knowledge-Based Systems,2014,57(2):168-180.
[7] 袁津生,毛新武.基于组合特征的中文新闻网页关键词提取方法 [J].计算机工程与应用,2014,50(19):222-226.
(YUAN Jin-sheng,MAO Xin-wu.Keyword extraction from chinese news Web pages based on multi-features [J].Computer Engineering and Applications,2014,50(19):222-226.)
[8] 孟海东,肖银龙,宋宇辰.基于Hadoop的Dirichlet朴素贝叶斯文本分类算法[J].现代电子技术,2016,39(4):29-33.
(MENG Hai-dong,XIAO Yin-long,SONG Yu-chen.Classification algorithm for Dirichlet Naive Bayes text based on Hadoop[J].Modern Electronics Technique,2016,39(4):29-33.)
[9] 潘志文,柏灼,谢政.基于Lucene的Web信息检索系统设计与实现 [J].软件导刊,2014(10):88-90.
(PAN Zhi-wen,BAI Zhuo,XIE Zheng.Design and implementation of web information retrieval system based on lucene [J] Software Guide,2014(10):88-90.)
[10]罗芳,李春花,周可,等.基于多属性的海量Web数据关联存储及检索系统 [J].计算机工程与科学,2014,36(3):404-410.
(LUO Fang,LI Chun-hua,ZHOU Ke,et al.An associated storage and retrieval system of massive web data based on multi-attributes [J].Computer Engineering & Science,2014,36(3):404-410.)
[11]Zhu J,Xie Q,Wong W H,et al.Exploiting link structure for web page genre identification [J].Data Mining & Knowledge Discovery,2016,30(3):550-575.
[12]周炜,牛连强,王斌.面向社交网络的认证模型 [J].沈阳工业大学学报,2016,38(5):545-550.
(ZHOU Wei,NIU Lian-qiang,WANG Bin.Authentication models faced on social networks [J].Journal of Shenyang University of Technology,2016,38(5):545-550.)
[13]俞浩亮,王秋森,冯旭鹏,等.基于特征加权的网络不良内容识别方法[J].现代电子技术,2016,39(3):76-79.
(YU Hao-liang,WANG Qiu-sen,FENG Xu-peng,et al.Feature weighting based identification method for network undesirable content[J].Modern Electronics Technique,2016,39(3):76-79.)
[14]Jiang L,Li C,Wang S,et al.Deep feature weighting for naive Bayes and its application to text classification [J].Engineering Applications of Artificial Intelligence,2016,52(3):26-39.
[15]夏莘媛,戴静,潘用科,等.基于贝叶斯证据框架下SVM的油层识别模型研究 [J].重庆邮电大学学报(自然科学版),2016,28(2):260-264.
(XIA Xin-yuan,DAI Jing,PAN Yong-ke,et al.Oil layer recognition model based on SVM within Bayesian evidence framework [J].Journal of Chongqing University of Posts and Telecommunications(Natural Science Edition),2016,28(2):260-264.)
[16]Hernndez I,Rivero C R,Ruiz D,et al.CALA:links automatically based on their URL [J].Journal of Systems & Software,2016,115:130-143.
QIN Peng1, CAO Tian-jie2
(1.Department of Computer Science and Information Technology, Liupanshui Normal University, Liupanshui 553004, China; 2.School of Computer Science and Technology, China University of Mining and Technology, Xuzhou 221116, China)
Abstract:Aiming at the situation that the accuracy and recall rate of traditional web page classification are not high and the classification efficiency is low, a web page pre-classification algorithm based on Naive Bayes classification was proposed.According to the online activity situation of users, the relevant websites were extracted, the contents and keywords of web pages were analyzed, and the classification was performed with the Naive Bayes algorithm.According to the browse situation of users on various web pages, the behavior characteristics of users were analyzed.The improved web text weight calculation method was adopted, the web site pre-classification mechanism was introduced, and the processing efficiency of data and classification accuracy were improved.The results show that the web site classification algorithm is accurate, can fully explore the interest and preference of users, and can be applied in both the commercial popularization and forensic evidence as the data algorithm for the behavior analysis of users.
Key words:web page keyword; Naive Bayes; web page classification; behavior characteristic; weight calculation method; website pre-classification; business promotion; forensic evidence
收稿日期:2017-03-29.
基金项目:贵州省科学技术基金计划资助项目(20157606);贵州省教育厅青年科技人才成长资助项目(2016267).
作者简介:秦 鹏(1986-),男,贵州六枝人,讲师,硕士,主要从事计算机人工智能及信息安全等方面的研究.
* 本文已于2017-12-21 14∶47在中国知网优先数字出版.网络出版地址:http://kns.cnki.net/kcms/detail/21.1189.T.20171220.1758.010.html
doi:10.7688/j.issn.1000-1646.2018.01.15
中图分类号:TP 181
文献标志码:A
文章编号:1000-1646(2018)01-0082-06
(责任编辑:景 勇 英文审校:尹淑英)